使用hbase的目的是为了海量数据的随机读写,但是在实际使用中却发现针对随机读的优化和gc是一个很大的问题,而且hbase的数据是存储在Hdfs,而Hdfs是面向流失数据访问进行设计的,就难免带来效率的下降。下面介绍一下Facebook Message系统在HBase online storage场景下的一个案例(《Apache Hadoop Goes Realtime at Facebook》, SIGMOD 2011),最近他们在存储领域顶级会议FAST2014上发表了一篇论文《Analysis of HDFS Under HBase: A Facebook Messages Case Study》分析了他们在使用HBase中遇到的一些问题和解决方案。该论文首先讲了Facebook的分析方法包括tracing/analysis/simulation,FM系统的架构和文件与数据构成等,接下来开始分析FM系统在性能方面的一些问题,并提出了解决方案。
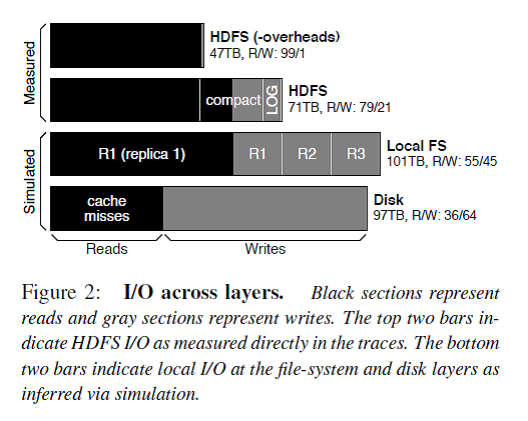
Figure 2描述了每一层的I/O构成,解释了在FM系统对外请求中读占主导,但是由于logging/compaction/replication/caching导致写被严重放大。
- HBase的设计是分层结构的,依次是DB逻辑层、FS逻辑层、底层系统逻辑层。DB逻辑层提供的对外使用的接口主要操作是put()和get()请求,这两个操作的数据都要写到HDFS上,其中读写比99/1(Figure 2中第一条)。
- 由于DB逻辑层内部为了保证数据的持久性会做logging,为了读取的高效率会做compaction,而且这两个操作都是写占主导的,所以把这两个操作(overheads)加上之后读写比为79/21(Figure 2中第二条)。
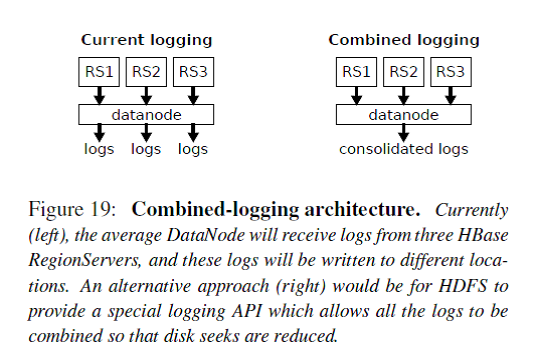
- 相当于调用put()操作向HBase写入的数据都是写入了两份:一份写入内存Memstore然后flush到HFile/HDFS,另一份通过logging直接写HLog/HDFS。Memstore中积累一定量的数据才会写HFile,这使得压缩比会比较高,而写HLog要求实时append record导致压缩比(HBASE-8155)相对较低,导致写被放大4倍以上。 Compaction操作就是读取小的HFile到内存merge-sorting成大的HFile然后输出,加速HBase读操作。Compaction操作导致写被放大17倍以上,说明每部分数据平均被重复读写了17次,所以对于内容不变的大附件是不适合存储在HBase中的。由于读操作在FM业务中占主要比例,所以加速读操作对业务非常有帮助,所以compaction策略会比较激进。
HBase的数据reliable是靠HDFS层保证的,即HDFS的三备份策略。那么也就是上述对HDFS的写操作都会被转化成三倍的local file I/O和两倍的网络I/O。这样使得在本地磁盘I/O中衡量读写比变成了55/45。 - 然而由于对本地磁盘的读操作请求的数据会被本地OS的cache缓存,那么真正的读操作是由于cache miss引起的读操作的I/O量,这样使得读写比变成了36/64,写被进一步放大。 另外Figure 3从I/O数据传输中真正业务需求的数据大小来看各个层次、各个操作引起的I/O变化。除了上面说的,还发现了整个系统最终存储在磁盘上有大量的cold data(占2/3),所以需要支持hot/cold数据分开存储。
总的来说,HBase stack的logging/compaction/replication/caching会放大写I/O,导致业务逻辑上读为主导的HBase系统在地层实际磁盘I/O中写占据了主导。
FM系统的主要文件类型和大小

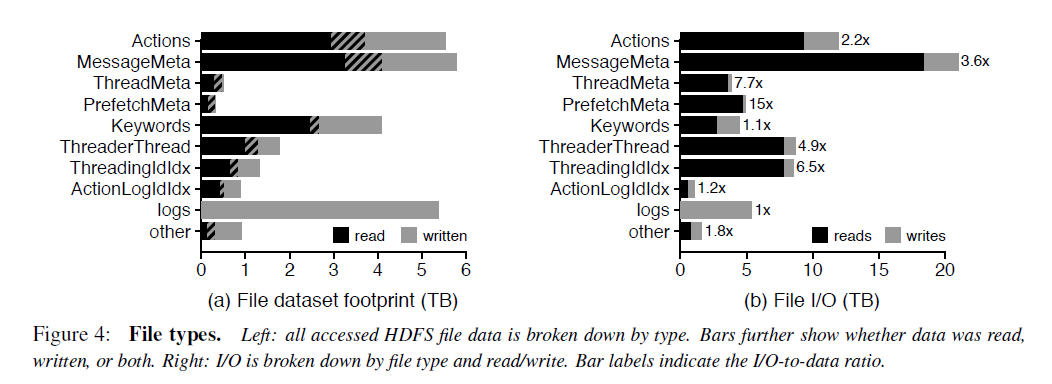
对于每个column family的文件,90%是小于15M的。但是少量的特别大的文件会拉高column family的平均文件大小。例如MessageMeta这个column family的平均文件大小是293M。从这些文件的生命周期来看,大部分FM的数据存储在large,long-lived files,然而大部分文件却是small, short-lived。这对HDFS的NameNode提出了很大的挑战,因为HDFS设计的初衷是为了存储少量、大文件准备的,所有的文件的元数据是存储在NameNode的内存中的,还有有NameNode federation。
FM系统的主要I/O访问类型
下面从temporal locality, spatial locality, sequentiality的角度来看。
73.7%的数据只被读取了一次,但是1.1%的数据被读取了至少64次。也就是说只有少部分的数据被重复读取了。但是从触发I/O的角度,只有19%的读操作读取的是只被读取一次的数据,而大部分I/O是读取那些热数据。
在HDFS这一层,FM读取数据没有表现出sequentiality,也就是说明high-bandwidth, high-latency的机械磁盘不是服务读请求的理想存储介质。而且对数据的读取也没有表现出spatial locality,也就是说I/O预读取也没啥作用。
解决方案1. Flash/SSD作为cache使用
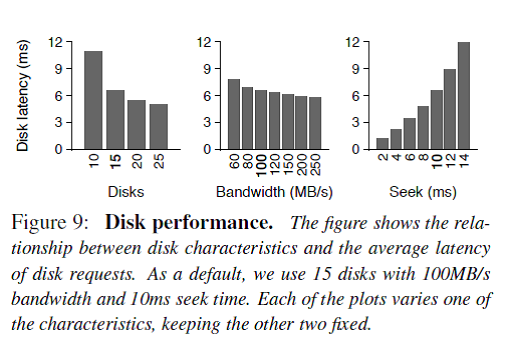
由于少部分同样的数据会被经常读取,所以一个大的cache能够把80%左右的读取操作拦截而不用触发磁盘I/O,而且只有这少部分的hot data需要被cache。那么拿什么样的存储介质做cache呢?Figure 11说明如果拿足够大的Flash做二级缓存,cache命中率会明显提高,同时cache命中率跟内存大小关系并不大。
注:关于拿Flash/SSD做cache,可以参考HBase BucketBlockCache(HBASE-7404)
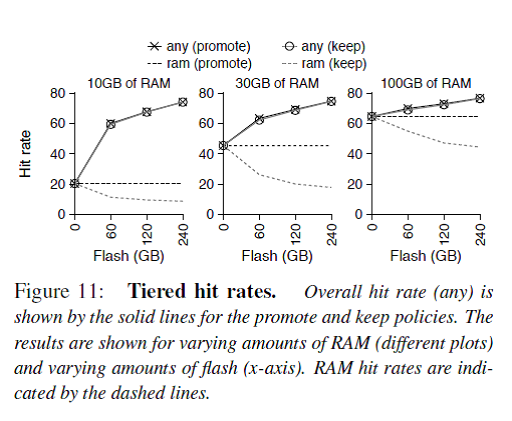
说完加速读的cache,接着讨论了Flash作为写buffer是否会带来性能上的提升。由于HDFS写操作只要数据被DataNode成功接收到内存中就保证了持久性(因为三台DataNode同时存储,所以认为从DataNode的内存flush到磁盘的操作不会三个DataNode都失败),所以拿Flash做写buffer不会提高性能。虽然加写buffer会使后台的compaction操作降低他与前台服务的I/O争用,但是会增加很大复杂度,所以还是不用了。最后他们给出了结论就是拿Flash做写buffer没用。
然后他们还计算了,在这个存储栈中加入Flash做二级缓存不但能提升性能达3倍之多,而且只需要增加5%的成本,比加内存性价比高很多。
2.分层架构的缺点和改进方案
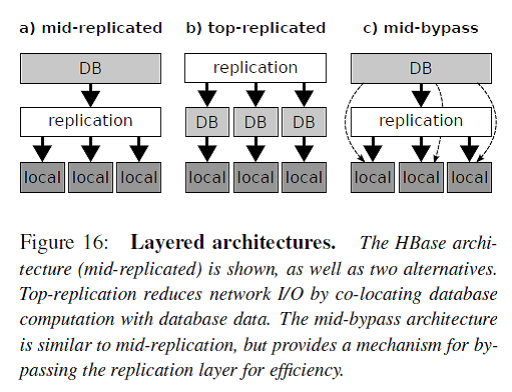
如Figure 16所示,一般分布式数据库系统分为三个层次:db layer/replication layer/local layer。这种分层架构的最大优点是简洁清晰,每层各司其职。例如db layer只需要处理DB相关的逻辑,底层的存储认为是available和reliable的。
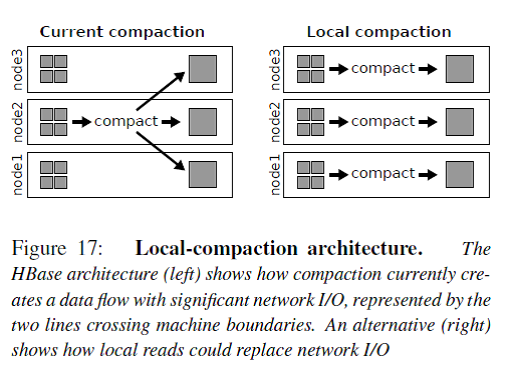
HBase是图中a)的架构,数据的冗余replication由HDFS来负责。但是这个带来一个问题就是例如compaction操作会读取多个三备份的小文件到内存merge-sorting成一个三备份的大文件,这个操作只能在其中的一个RS/DN上完成,那么从其他RS/DN上的数据读写都会带来网络传输I/O。
图中b)的架构就是把replication层放到了DB层的上面,Facebook举的例子是Salus,不过我对这个东西不太熟悉。我认为Cassandra就是这个架构的。这个架构的缺点就是DB层需要处理底层文件系统的问题,还要保证和其他节点的DB层协调一致,太复杂了。
图中c)的架构是在a的基础上的一种改进,Spark使用的就是这个架构。HBase的compaction操作就可以简化成join和sort这样两个RDD变换。