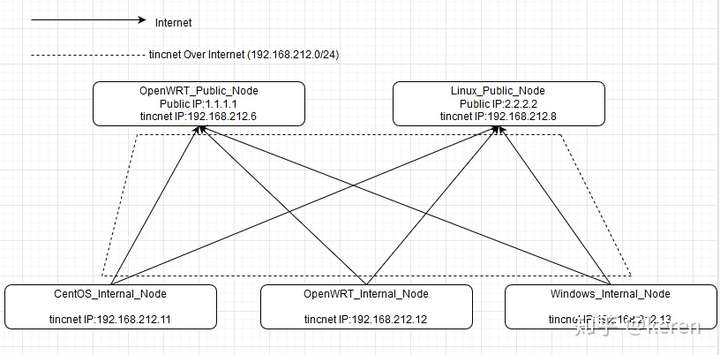
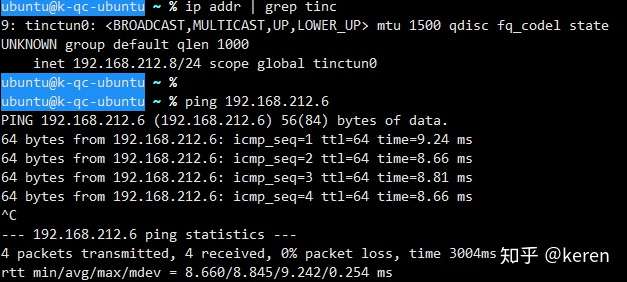
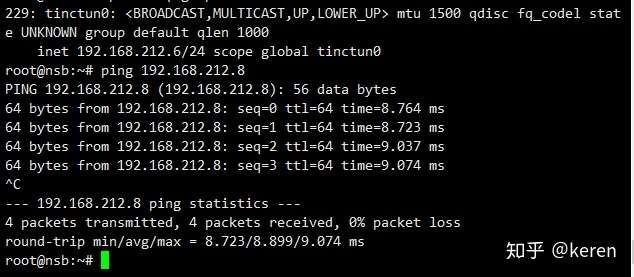
前言
關注 RxJS 已經好一段時間了,最早知道這個東西是因為 redux-observable,是一個 redux 的 middleware,Netflix 利用它來解決複雜的非同步相關問題,那時候我連redux-saga都還沒搞懂,沒想到就又有新的東西出來了。
半年前花了一些時間,找了很多網路上的資料,試圖想要搞懂這整個東西。可是對我來說,很多教學的步調都太快了,不然就是講得太仔細,反而讓初學者無所適從。
這次有機會在公司的新專案裡面嘗試導入redux-observable,身為提倡要導入的人,勢必要對這東西有一定的瞭解。秉持著這個想法,上週認真花了點時間再次把相關資源都研究了一下,漸漸整理出一套「我覺得應該可以把 RxJS 講得更好懂」的方法,在這邊跟大家分享一下。
在開始之前,要先大力稱讚去年 iT 邦幫忙鐵人賽的 Web 組冠軍:30 天精通 RxJS,這系列文章寫得很完整,感受得出來作者下了很多功夫在這上面。看完這篇之後如果對更多應用有興趣的,可以去把這系列的文章讀完。
好,那就讓我們開始吧!
請你先忘掉 RxJS
沒錯,你沒看錯。
要學會 RxJS 的第一件事情就是:忘記它。
忘記有這個東西,完全忘記,先讓我講幾個其他東西,等我們需要講到 RxJS 的時候我會再提醒你的。
在我們談到主角之前,先來做一些有趣的事情吧!
程式基礎能力測試
先讓我們做一個簡單的練習題暖身,題目是這樣的:
有一個陣列,裡面有三種類型的資料:數字、a~z組成的字串、數字組成的字串,請你把每個數字以及數字組成的字串乘以二之後加總
範例輸入:[1, 5, 9, 3, ‘hi’, ‘tb’, 456, ’11’, ‘yoyoyo’]
你看完之後應該會說:「這有什麼難的?」,並且在一分鐘以內就寫出下面的程式碼:
const source = [1, 5, 9, 3, 'hi', 'tb', 456, '11', 'yoyoyo'];
let total = 0;
for (let i = 0; i < source.length; i++) {
let num = parseInt(source[i], 10);
if (!isNaN(num)) {
total += num * 2;
}
}
相信大家一定都是很直覺的就寫出上面的程式碼,但如果你是個 functional programming 的愛好者,你可能會改用另外一種思路來解決問題:
const source = [1, 5, 9, 3, 'hi', 'tb', 456, '11', 'yoyoyo'];
let total = source
.map(x => parseInt(x, 10))
.filter(x => !isNaN(x))
.map(x => x * 2)
.reduce((total, value) => total + value )
一開始的例子叫做Imperative(命令式),用陣列搭配一堆函式的例子叫做Declarative(聲明式)。如果你去查了一下定義,應該會看到這兩個的解釋:
Imperative 是命令機器去做事情(how),這樣不管你想要的是什麼(what),都會按照你的命令實現;Declarative 是告訴機器你想要的是什麼(what),讓機器想出如何去做(how)
好,你有看懂上面這些在說什麼嗎?
我是沒有啦。
所以讓我們再看一個例子,其實 Declarative 你已經常常在用了,只是你不知道而已,那就是 SQL:
SELECT * from dogs INNER JOIN owners WHERE dogs.owner_id = owners.id
這句話就是:我要所有狗的資料加上主人的資料。
我只有說「我要」而已,那要怎麼拿到這些資料?我不知道,我也不用知道,都讓 SQL 底層決定怎麼去操作就好。
如果我要自己做出這些資料,在 JavaScript 裡面我必須這樣寫(程式碼取自声明式编程和命令式编程的比较):
var dogsWithOwners = []
var dog, owner
for(var di=0; di < dogs.length; di++) {
dog = dogs[di]
for(var oi=0; oi < owners.length; oi++) {
owner = owners[oi]
if (owner && dog.owner_id == owner.id) {
dogsWithOwners.push({
dog: dog,
owner: owner
})
}
}
}
應該可以大致體驗出兩者的差別吧?後者你必須自己一步步去決定該怎麼做,而前者只是僅僅跟你說:「我想要怎樣的資料」而已。
接著我們再把目光放回到把數字乘以二相加的那個練習。對我來說,最大的不同點是後面那個用陣列搭配函式的例子,他的核心概念是:
把原始資料經過一連串的轉換,變成你想要的資訊
這點超級重要,因為在一開始的例子中,我們是自己一步步去 parse,去檢查去相加,得出數字的總和。而後面的那個例子,他是把原始的資料(陣列),經過一系列的轉換(map, filter, reduce),最後變成了我們想要的答案。
畫成圖的話,應該會長這樣(請原諒我偷懶把乘二的部分拿掉了,但意思不影響):
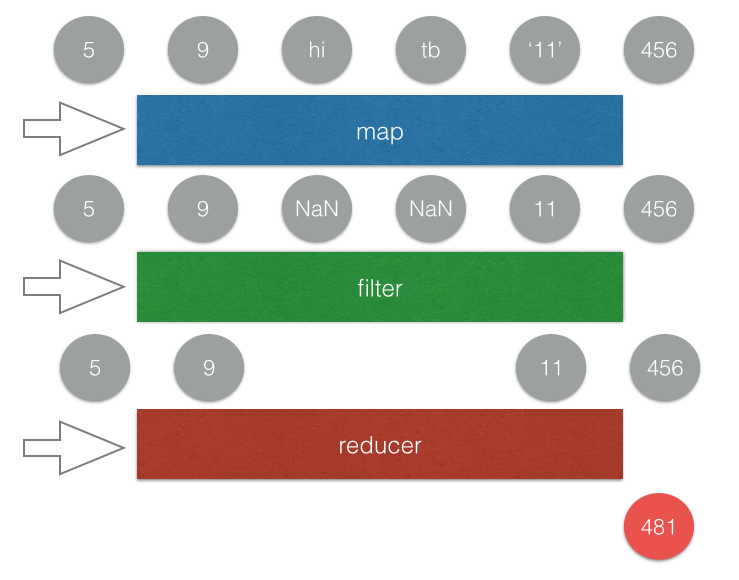
把原始資料經過一連串的轉換,最後變成你想要的答案,這點就是後者最大的不同。只要你有了這個基礎知識之後,再來看 RxJS 就不會覺得太奇怪了。
Reactive Programming
談到 RxJS 的時候,都會談到 Reactive 這個詞,那什麼是 Reactive 呢?可以從英文上的字義來看,這個單字的意思是:「反應、反應性的」,意思就是你要對一些事情做出反應。
所以 Reactive 其實就是在講說:「某些事情發生時,我能夠做出反應」。
讓我們來舉一個大家非常熟知的例子:
window.addEventListener('click', function(){
console.log('click!');
})
我們加了一個 event listener 在 window 上面,所以我們可以監聽到這個事件,每當使用者點擊的時候就列印出 log。換句話說,這樣就是:「當 window 被點擊時,我可以做出反應」。
正式進入 RxJS
如果你去看 ReactiveX 的網頁,你會發現他有明確的定義 ReactiveX:
ReactiveX is a combination of the best ideas from
the Observer pattern, the Iterator pattern, and functional programming
第一個 Observer pattern 就像是 event listener 那樣,在某些事情發生時,我們可以對其作出反應;第二個 Iterator pattern 我們跳過不講,我認為暫時不影響理解;第三個就像是一開始的例子,我們可以把一個陣列經過多次轉換,轉換成我們想要的資料。
在 Reactive Programming 裡面,最重要的兩個東西叫做 Observable 跟 Observer,其實一開始讓我最困惑的點是因為我英文不好,不知道這兩個到底誰是觀察的誰是被觀察的。
先把它們翻成中文,Observable 就是「可被觀察的」,Observer 就是所謂的「觀察者」。
這是什麼意思呢?就如同上面的例子一樣,當(可被觀察的東西)有事情發生,(Observer,觀察者)就可以做出反應。
直接舉一個例子你就知道了:
Rx.Observable.fromEvent(window, 'click')
.subscribe(e => {
console.log('click~');
})
上面這段程式碼跟我幫 window 加上 event listener 在做的事情完全一樣,只是這邊我們使用了 RxJS 提供的方法叫做fromEvent,來把一個 event 轉成 Observable(可被觀察的),並且在最後加上 subscribe。
這樣寫就代表說我訂閱了這個 Observable,只要有任何事情發生,就會執行我傳進去的 function。
所以到底什麼是 Observable?
Observable 就是一個可被觀察的對象,這個對象可以是任何東西(例如說上述例子就是 window 的 click 事件),當有新資料的時候(例如說新的點擊事件),你就可以接收到這個新資料的資訊並且做出反應。
比起 Observable 這個冷冰冰的說法,我更喜歡的一個說法是 stream,資料流。其實每一個 Observable 就是一個資料流,但什麼是資料流?你就想像成是會一直增加元素的陣列就好了,有新的事件發生就 push 進去。如果你喜歡更專業一點的說法,可以叫它:「時間序列上的一連串資料事件」(取自 Reactive Programming 簡介與教學(以 RxJS 為例))
或是我再舉一個例子,stream 的另外一個解釋就是所謂的「串流影片」,意思就是隨著你不斷播放,就會不斷下載新的片段進來。此時你腦中應該要有個畫面,就是像水流那樣,不斷有新的東西流進來,這個東西就叫做 stream。

(圖片取自 giphy)
我理解資料流了,然後呢?
上面有說過,我們可以把任何一個東西轉成 Observable,讓它變成資料流,可是這不就跟 addEventListener 一樣嗎?有什麼特別的?
有,還真的比較特別。
希望你沒有忘記我們剛開始做的那個小練習,就是把一個陣列透過一系列轉換,變成我們要的資料的那個練習。我剛剛有說,你可以把 Observable 想成是「會一直增加元素的陣列」,這代表什麼呢?
代表我們也可以把 Observable 做一系列的轉換!我們也可以用那些用在陣列上的 function!
Rx.Observable.fromEvent(window, 'click')
.map(e => e.target)
.subscribe(value => {
console.log('click: ', value)
})
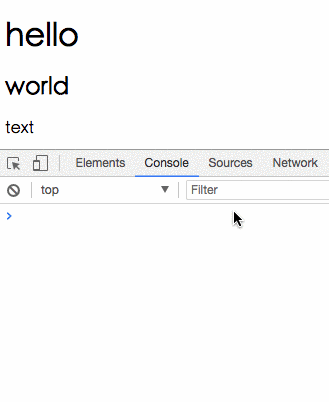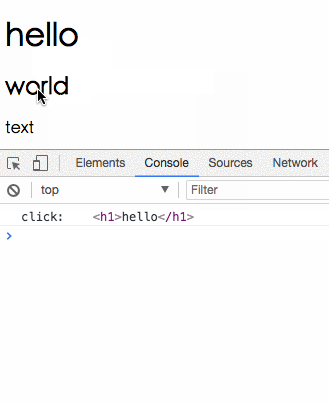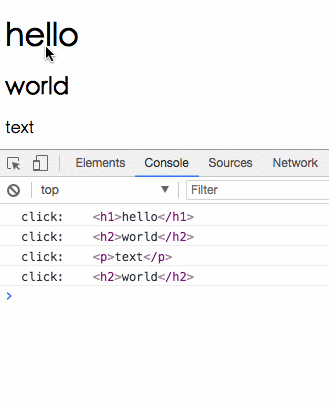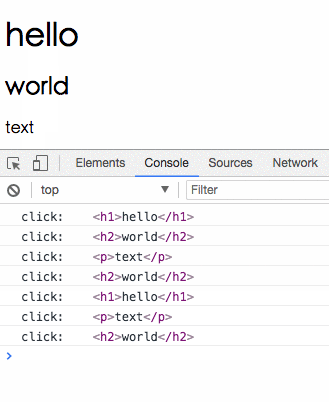
我們把 click 事件經過 map 轉換為點擊到的 element,所以當我們最後在 subscribe 的時候,收到的 value 就會是我們點擊的東西。
接著來看一個稍微進階一點的例子:
Rx.Observable.fromEvent(window, 'click')
.map(e => 1)
.scan((total, now) => total + now)
.subscribe(value => {
document.querySelector('#counter').innerText = value;
})

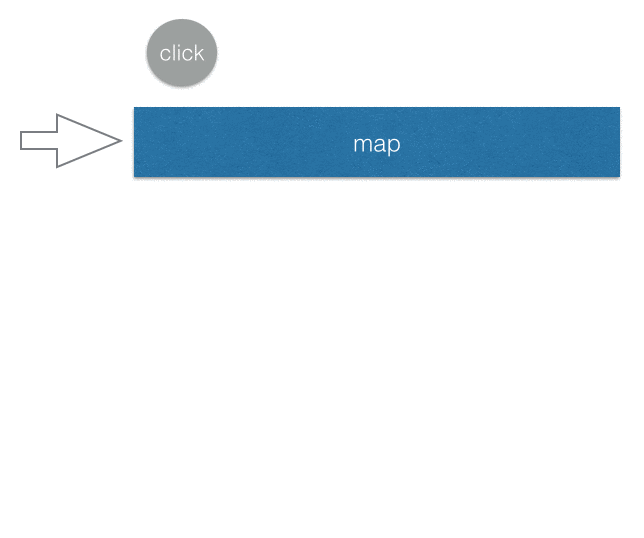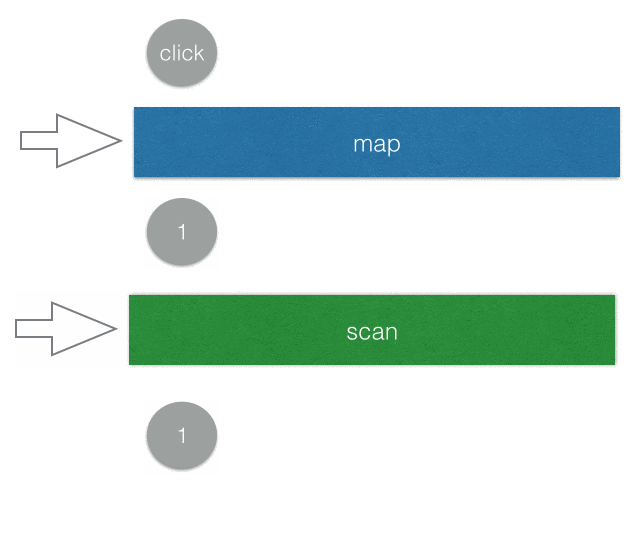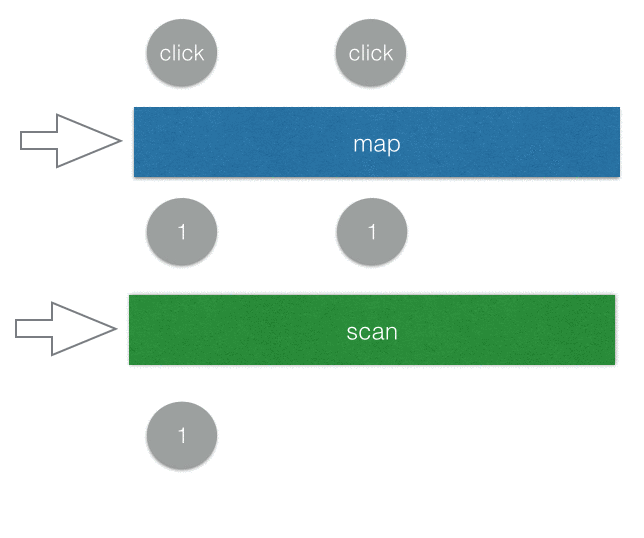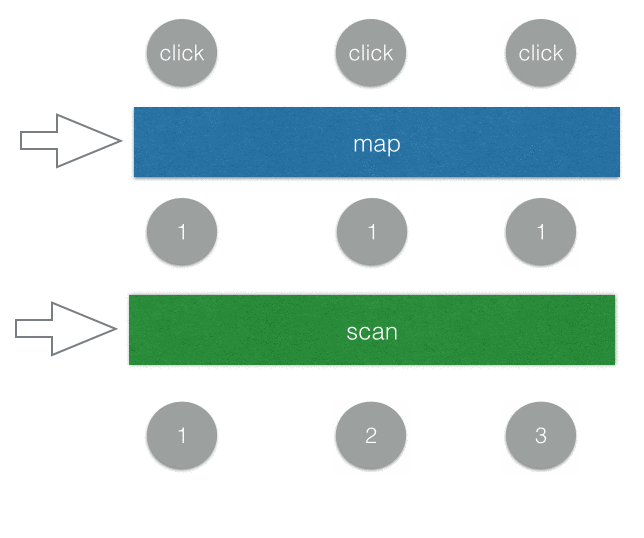
首先我們先把每一個 click 事件都透過map轉換成 1(或者你也可以寫成.mapTo(1)),所以每按一次就送出一個數字 1。scan的話其實就是我們一開始對陣列用的reduce,你可以想成是換個名字而已。透過scan加總以後傳給 subscriber,顯示在頁面上面。
就這樣簡單幾行,就完成了一個計算點擊次數的 counter。
可以用一個簡單的 gif 圖來表示上面的範例:
可是 Observable 不只這樣而已,接下來我們要進入到它最厲害的地方了。
威力無窮的組合技
如果把兩個陣列合併,會變成什麼?例如說[1, 2, 3]跟[4, 5, 6]?
這要看你指的「合併」是什麼,如果是指串接,那就是[1, 2, 3, 4, 5, 6],如果是指相加,那就是[5, 7, 9]。
那如果把兩個 Observable 合併會變成什麼?
Observable 跟陣列的差別就在於多了一個維度:時間。
Observable 是「時間序列上的一連串資料事件」,就像我前面講的一樣,可以看成是一個一直會有新資料進來的陣列。
我們先來看看一張很棒的圖,很清楚地解釋了兩個 Observable 合併會變成什麼:
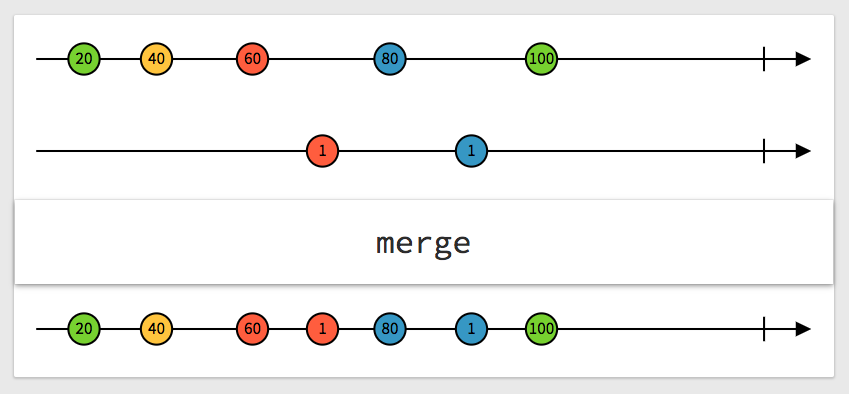
(取自:http://rxmarbles.com/#merge)
上面是一個 Observable,每一個圓點代表一個資料,下面也是一樣,把這兩個合併之後就變成最下面那一條,看圖解應該還滿好懂的,就像是把兩個時間軸合併一樣。
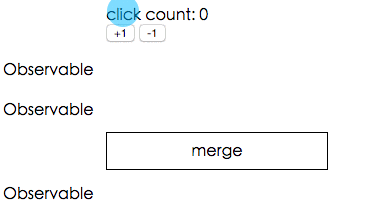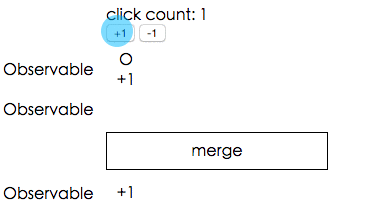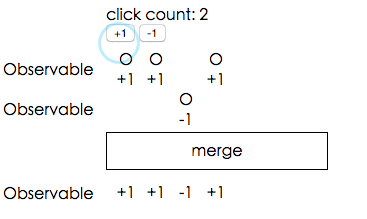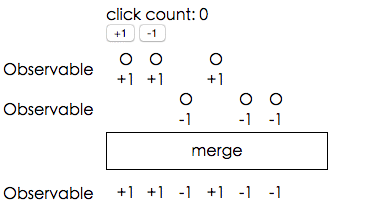
讓我們來看一個可以展現合併強大之處的範例,我們有 +1 跟 -1 兩個按鈕以及文字顯示現在的數字是多少:
該怎麼達成這個功能呢?基本的想法就是我們先把每個 +1 的 click 事件都通過mapTo變成數字 1,取叫 Observable_plus1 好了。再做出一個 Observable_minus1 是把每個 -1 的 click 事件都通過mapTo變成數字 -1。
把這兩個 Observable 合併之後,再利用剛剛提到的scan加總,就是目前應該要顯示的數字了!
Rx.Observable.fromEvent(document.querySelector('input[name=plus]'), 'click')
.mapTo(1)
.merge(
Rx.Observable.fromEvent(document.querySelector('input[name=minus]'), 'click')
.mapTo(-1)
)
.scan((total, now) => total + now)
.subscribe(value => {
document.querySelector('#counter').innerText = value;
})
如果你還是不懂的話,可以參考下面的精美範例,示範這兩個 Observable 是怎麼合在一起的(O代表點擊事件,+1跟-1則是mapTo之後的結果):
讓我們來比較一下如果不用 Observable 的話,程式碼會長怎樣:
var total = 0;
document.querySelector('input[name=plus]').addEventListener('click', () => {
total++;
document.querySelector('#counter').innerText = total;
})
document.querySelector('input[name=minus]').addEventListener('click', () => {
total--;
document.querySelector('#counter').innerText = total;
})
有沒有發覺兩者真的差別很大?就如同我之前所說的,是兩種完全不同的思考模式,所以 Reactive Programming 困難的地方不是在於理解,也不是在於語法(這兩者相信你目前都有些概念了),而是在於換一種全新的思考模式。
以上面的寫法來說,就是告訴電腦:「按下加的時候就把一個變數 +1,然後更改文字;按下減的時候就 -1 並且也更改文字」,就可以達成計數器的功能。
以 Reactive 的寫法,就是把按下加當成一個資料流,把按下減也當成一個資料流,再透過各種 function 把這兩個流轉換並且合併起來,讓最後的那個流就是我們想要的結果(計數器)。
你現在應該能體會到我一開始說的了:「把原始資料經過一連串的轉換,最後變成你想要的答案」,這點就是 Reactive Programming 最大的特色。
組合技中的組合技
我們來看一個更複雜一點的範例,是在 canvas 上面實現非常簡單的繪圖功能,就是滑鼠按下去之後可以畫畫,放開來就停止。

要實現這個功能很間單,canvas 提供lineTo(x, y)這個方法,只要在滑鼠移動時不斷呼叫這個方法,就可以不斷畫出圖形來。但有一點要注意的是當你在按下滑鼠時,應該先呼叫moveTo(x, y)把繪圖的點移到指定位置,為什麼呢?
假設我們第一次畫圖是在左上角,第二次按下滑鼠的位置是在右下角,如果沒有先用moveTo移動而是直接用lineTo的話,就會多一條線從左上角延伸到右下角。moveTo跟lineTo的差別就是前者只是移動,後者會跟上次的點連接在一起畫成一條線。

var canvas = document.getElementById('canvas');
var ctx = canvas.getContext('2d');
ctx.beginPath();
function draw(e){
ctx.lineTo(e.clientX,e.clientY);
ctx.stroke();
}
canvas.addEventListener('mousedown', function(e){
ctx.moveTo(e.clientX, e.clientY);
canvas.addEventListener('mousemove', draw);
})
canvas.addEventListener('mouseup', function(e){
canvas.removeEventListener('mousemove', draw);
})
那如果在 RxJS 裡面,該怎麼實作這個功能呢?
首先憑直覺,應該就是先加上mousedown的事件對吧!至少有個開頭。
Rx.Observable.fromEvent(canvas, 'mousedown')
.subscribe(e => {
console.log('mousedown');
})
可是滑鼠按下去之後應該要變成什麼?這個時候應該要開始監聽mousemove對吧,所以我們這樣寫,用mapTo把每一個mousedown的事件都轉換成mousemove的 Observable:
Rx.Observable.fromEvent(canvas, 'mousedown')
.mapTo(
Rx.Observable.fromEvent(canvas, 'mousemove')
)
.subscribe(value => {
console.log('value: ', value);
})
接著你看一下 console,你會發現每當我點擊的時候,console 就會印出FromEventObservable {_isScalar: false, sourceObj: canvas#canvas, eventName: "mousemove", selector: undefined, options: undefined}
仔細想一下你會發現也滿合理的,因為我用mapTo把每一個滑鼠按下去的事件轉成一個 mousemove 的 Observable,所以用 subscribe 訂閱之後拿到的東西就會是這個 Observable。如果畫成圖,大概長得像這樣:
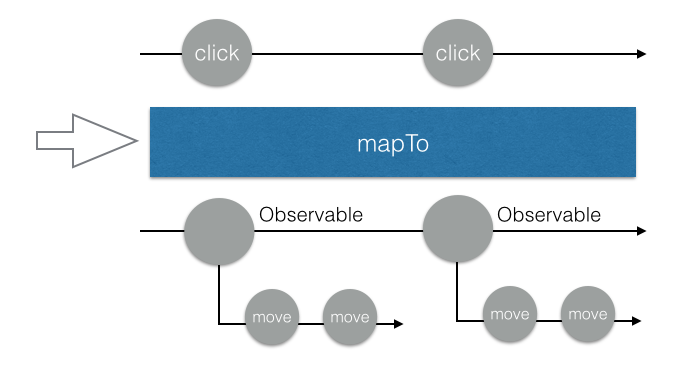
好了,那怎麼辦呢?我想要的其實不是 Observable 本身,而是屬於這個 Observable 裡面的那些東西啊!現在這個情形就是 Observable 裡面又有 Observable,有兩層,可是我想要讓它變成一層就好,該怎麼辦呢?
在此提供一個讓 Observable 變簡單的訣竅:
只要有問題,先想想 Array 就對了!
我前面有提過,可以把 Observable 看成是加上時間維度的進階版陣列,因此只要是陣列有的方法,Observable 通常也都會有。
舉例來說,一個陣列可能長這樣:[1, [2, 2.5], 3, [4, 5]]一共有兩層,第二層也是一個陣列。
如果想讓它變一層的話怎麼辦呢?壓平!
有用過 lodash 或是其他類似的 library 的話,你應該有聽過_.flatten這個方法,可以把這種陣列壓平,變成:[1, 2, 2.5, 3, 4, 5]。
用 flat 這個關鍵字去搜尋 Rx 文件的話,你會找到一個方法叫做 FlatMap,簡單來說就是先map之後再自動幫你壓平。
所以,我們可以把程式碼改成這樣:
Rx.Observable.fromEvent(canvas, 'mousedown')
.flatMap(e => Rx.Observable.fromEvent(canvas, 'mousemove'))
.subscribe(e => {
console.log(e);
})
當你點擊之後,會發現隨著滑鼠移動,console 會印出一大堆 log,就代表我們成功了。
畫成示意圖的話會變成這樣(為了方便說明,我把flatMap在圖片上變成map跟flatten兩個步驟):
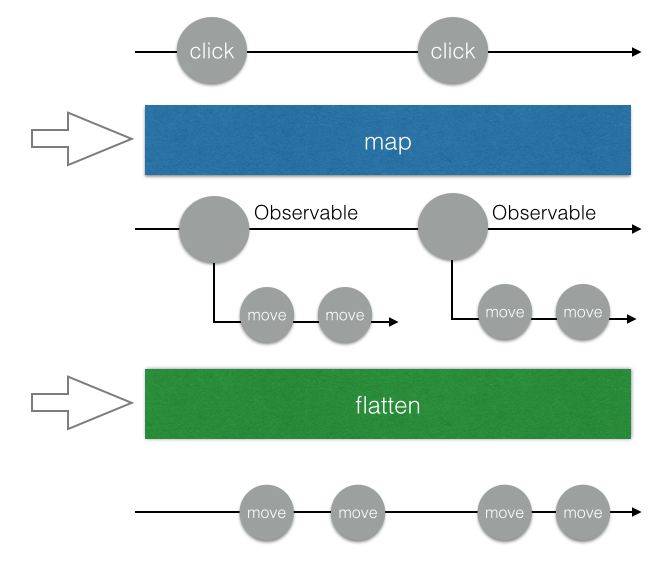
接下來呢?接下來我們要讓它可以在滑鼠鬆開的時候停止,該怎麼做呢?RxJS 有一個方法叫做takeUntil,意思就是拿到…發生為止,傳進去的參數必須是一個 Observable。
舉例來說,如果寫.takeUntil(window, 'click'),就表示如果任何window的點擊事件發生,這個 Observable 就會立刻終止,不會再送出任何資料。
應用在繪畫的例子上,我們只要把takeUntil後面傳的參數換成滑鼠鬆開就好!順便把subscribe跟畫畫的 function 也一起完成吧!
Rx.Observable.fromEvent(canvas, 'mousedown')
.flatMap(e => Rx.Observable.fromEvent(canvas, 'mousemove'))
.takeUntil(Rx.Observable.fromEvent(canvas, 'mouseup'))
.subscribe(e => {
draw(e);
})
改完之後馬上來實驗一下!滑鼠按下去之後順利開始畫圖,鬆開以後畫圖停止,完美!
咦,可是怎麼按下第二次就沒反應了?我們做出了一個「只能夠成功畫一次圖」的 Observable。
為什麼呢?我們可以先來看一下takeUntil的示意圖(取自:http://rxmarbles.com/#takeUntil)
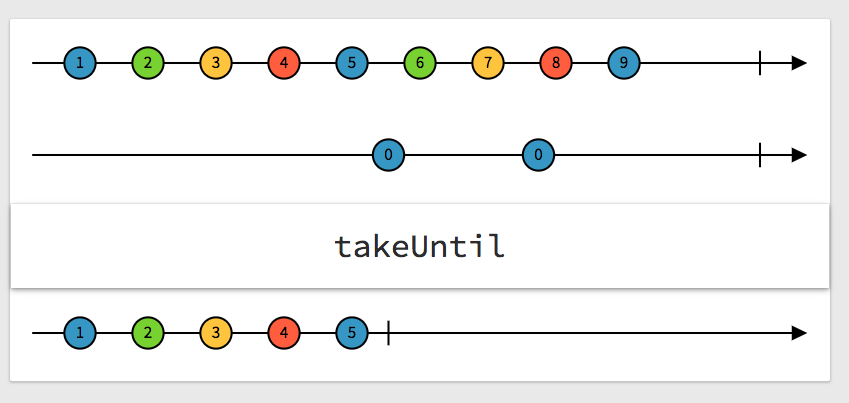
以我們的情形來說,就是只要mouseup事件發生,「整個 Observable」就會停止,所以只有第一次能夠畫圖成功。但我們想要的其實不是這樣,我們想要的是只有mousemove停止而已,而不是整個都停止。
所以,我們應該把takeUntil放在mousemove的後面,也就是:
Rx.Observable.fromEvent(canvas, 'mousedown')
.flatMap(e => Rx.Observable.fromEvent(canvas, 'mousemove')
.takeUntil(Rx.Observable.fromEvent(canvas, 'mouseup'))
)
.subscribe(e => {
draw(e);
})
這樣子裡面的那個mousemove的 Observable 就會在滑鼠鬆開時停止發送事件,而我們最外層的這個 Observable 監聽的是滑鼠按下,會一直監聽下去。
到這邊其實就差不多了,但還有一個小 bug 要修,就是我們沒有在mousedown的時候利用moveTo移動,造成我們一開始說的那個會把上次畫的跟這次畫的連在一起的問題。
那怎麼辦呢?我已經把mousedown事件轉成其他資料流了,我要怎麼在mousedown的時候做事?
有一個方法叫做do,就是為了這種情形而設立的,使用時機是:「你想做一點事,卻又不想影響資料流」,有點像是能夠針對不同階段 subscribe 的感覺,mousedown的時候 subscribe 一次,最後要畫圖的時候又 subscribe 一次。
Rx.Observable.fromEvent(canvas, 'mousedown')
.do(e => {
ctx.moveTo(e.clientX, e.clientY)
})
.flatMap(e => Rx.Observable.fromEvent(canvas, 'mousemove')
.takeUntil(Rx.Observable.fromEvent(canvas, 'mouseup'))
)
.subscribe(e => {
draw(e);
})
到這邊,我們就順利完成了畫圖的功能。
如果你想試試看你有沒有搞懂,可以實作看看拖拉移動物體的功能,原理跟這個很類似,都是偵測滑鼠的事件並且做出反應。
喝口水休息一下,下半場要開始了
上半場的目標在於讓你理解什麼是 Rx,並且掌握幾個基本概念:
- 一個資料流可以經過一系列轉換,變成另一個資料流
- 這些轉換基本上都跟陣列有的差不多,像是
map、filter、flatten等等
- 你可以合併多個 Observable,也可以把二維的 Observable 壓平
下半場專注的點則是在於實戰應用,並且圍繞著 RxJS 最適合的場景之一:API。
前面我們有提到說可以把 DOM 物件的 event 變成資料流,但除了這個以外,Promise 其實也可以變成資料流。概念其實也很簡單啦,就是 Promise 被 resovle 的時候就發送一個資料,被 reject 的時候就終止。
讓我們來看一個簡單的小範例,每按一次按鈕就會發送一個 request
function sendRequest () {
return fetch('https://jsonplaceholder.typicode.com/posts/1').then(res => res.json())
}
Rx.Observable.fromEvent(document.querySelector('input[name=send]'), 'click')
.flatMap(e => Rx.Observable.fromPromise(sendRequest()))
.subscribe(value => {
console.log(value)
})
這邊用flatMap的原因跟剛才的畫圖範例一樣,我們要在按下按鈕時,把原本的資料流轉換成新的資料流,如果只用map的話,會變成一個二維的 Observable,所以必須要用flatten把它壓平。
你可以試試看把flatMap改成map,你最後 subscribe 得到的值就會是一堆 Observable 而不是你想要的資料。
知道怎麼用 Rx 來處理 API 之後,就可以來做一個經典範例了:AutoComplete。
我在做這個範例的時候有極大部分參考30 天精通 RxJS(19): 實務範例 – 簡易 Auto Complete 實作、Reactive Programming 簡介與教學(以 RxJS 為例)以及构建流式应用—RxJS详解,再次感謝這三篇文章。
為了要讓大家能夠體會 Reactive Programming 跟一般的有什麼不一樣,我們先用老方法做出這個 Auto Complete 的功能吧!
先來寫一下最底層的兩個函式,負責抓資料的以及 render 建議清單的,我們使用維基百科的 API 來當作範例:
function searchWikipedia (term) {
return $.ajax({
url: 'http://en.wikipedia.org/w/api.php',
dataType: 'jsonp',
data: {
action: 'opensearch',
format: 'json',
search: term
}
}).promise();
}
function renderList (list) {
$('.auto-complete__list').empty();
$('.auto-complete__list').append(list.map(item => '<li>' + item + '</li>'))
}
這邊要注意的一個點是維基百科回傳的資料會是一個陣列,格式如下:
[你輸入的關鍵字, 關鍵字清單, 每個關鍵字的介紹, 每個關鍵字的連結]
[
"dd",
["Dd", "DDR3 SDRAM", "DD tank"],
["", "Double data rate type three SDRAM (DDR3 SDRAM)", "DD or Duplex Drive tanks"],
[https://en.wikipedia.org/wiki/Dd", "https://en.wikipedia.org/wiki/DDR3_SDRAM", "...略"]
]
在我們的簡單示範中,只需要取 index 為 1 的那個關鍵字清單就好了。而renderList這個 function 則是傳進一個陣列,就會把陣列內容轉成li顯示出來。
有了這兩個最基礎的 function 之後,就可以很輕易地完成 Auto Complete 的功能:
document.querySelector('.auto-complete input').addEventListener('input', (e) => {
searchWikipedia(e.target.value).then((data) => {
renderList(data[1])
})
})
程式碼應該很好懂,就是每次按下輸入東西的時候去 call api,把回傳的資料餵給renderList去渲染。
最基本的功能完成了,我們要來做一點優化,因為這樣子的實作其實是有一些問題的。
第一個問題,現在只要每打一個字就會送出一個 request,可是這樣做其實有點浪費,因為使用者可能快速的輸入了:java想要找相關的資料,他根本不在乎j、ja、jav這三個 request。
要怎麼做呢?我們就改寫成如果 250ms 裡面沒有再輸入新的東西才發送 request 就好,就可以避免這種多餘的浪費。
這種技巧稱作debounce,實作上也很簡單,就是利用setTimeout跟clearTimeout。
var timer = null;
document.querySelector('.auto-complete input').addEventListener('input', (e) => {
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(() => {
searchWikipedia(e.target.value).then((data) => {
renderList(data[1])
})
}, 250)
})
在 input 事件被觸發之後,我們不直接做事情,而是設置了一個 250ms 過後會觸發的 timer,如果 250ms 內 input 再次被觸發的話,我們就把上次的 timer 清掉,再重新設置一個。
如此一來,就可以保證使用者如果在短時間內不斷輸入文字的話,不會送出相對應的 request,而是會等到最後一個字打完之後的 250 ms 才發出 request。
解決了第一個問題之後,還有一個潛在的問題需要解決。
假設我現在輸入a,接著刪除然後再輸入b,所以第一個 request 會是a的結果,第二個 request 會是b的結果。我們假設 server 出了一點問題,所以第二個的 response 反而比第一個還先到達(可能b的搜尋結果有 cache 但是a沒有),這時候就會先顯示b的內容,等到第一個 response 回來時,再顯示a的內容。
可是這樣 UI 就有問題了,我明明輸入的是b,怎麼 auto complete 的推薦關鍵字是a開頭?
所以我們必須要做個檢查,檢查返回的資料跟我現在輸入的資料是不是一致,如果一致的話才 render:
var timer = null;
document.querySelector('.auto-complete input').addEventListener('input', (e) => {
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(() => {
searchWikipedia(e.target.value).then((data) => {
if (data[0] === document.querySelector('.auto-complete input').value) {
renderList(data[1])
}
})
}, 250)
})
到這裡應該就差不多了,該有的功能都有了。
接著,讓我們來挑戰用 RxJS 實作吧!
首先,先從簡單版的開始做,就是不包含 debounce 跟上面 API 順序問題的實作,監聽 input 事件轉換成 request,然後用flatMap壓平,其實就跟上面的流程差不多:
Rx.Observable
.fromEvent(document.querySelector('.auto-complete input'), 'input')
.map(e => e.target.value)
.flatMap(value => {
return Rx.Observable.from(searchWikipedia(value)).map(res => res[1])
})
.subscribe(value => {
renderList(value);
})
這邊用了兩個map,一個是把e轉成e.target.value,一個是把傳回來的結果轉成res[1],因為我們只需要關鍵字列表,其他的東西其實都不用。
那要如何實作debounce的功能呢?
RxJS 已經幫你實作好了,所以你只要加上.debounceTime(250)就好了,就是這麼簡單。
Rx.Observable
.fromEvent(document.querySelector('.auto-complete input'), 'input')
.debounceTime(250)
.map(e => e.target.value)
.flatMap(value => {
return Rx.Observable.from(searchWikipedia(value)).map(res => res[1])
})
.subscribe(value => {
renderList(value);
})
還有最後一個問題要解決,那就是剛才提到的 request 的順序問題。
Observable 有一個不同的解法,我來解釋給大家聽聽。
其實除了flatMap以外,還有另外一種方式叫做switchMap,他們的差別在於要怎麼把 Observable 給壓平。前者我們之前介紹過了,就是會把每一個二維的 Observable 都壓平,並且「每一個都執行」。
而switchMap的差別在於,他永遠只會處理最後一個 Observable。拿我們的例子來說,假設第一個 request 還沒回來的時候,第二個 request 就發出去了,那我們的 Observable 就只會處理第二個 request,而不管第一個。
第一個還是會發送,還是會接收到資料,只是接收到資料以後不會再把這個資料 emit 到 Observable 上面,意思就是根本沒人理這個資料了。
可以看一下簡陋的圖解,flatMap每一個 promise resolve 之後的資料都會被發送到我們的 Observable 上面:
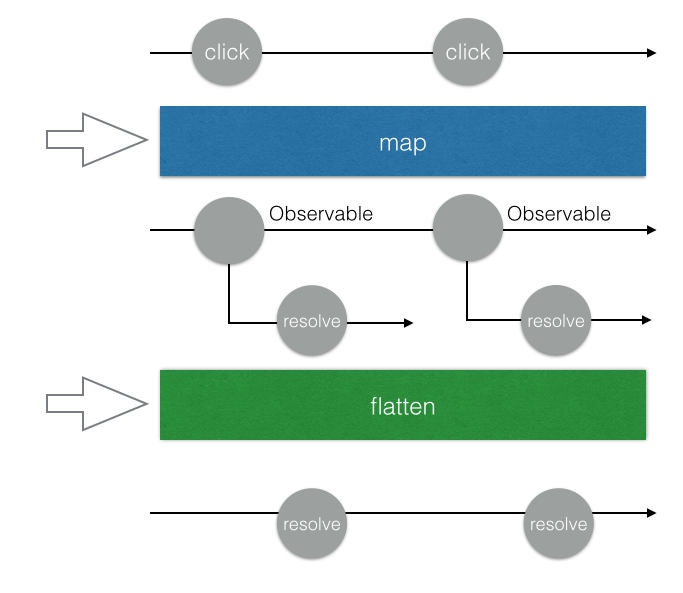
而switchMap只會處理最後一個:
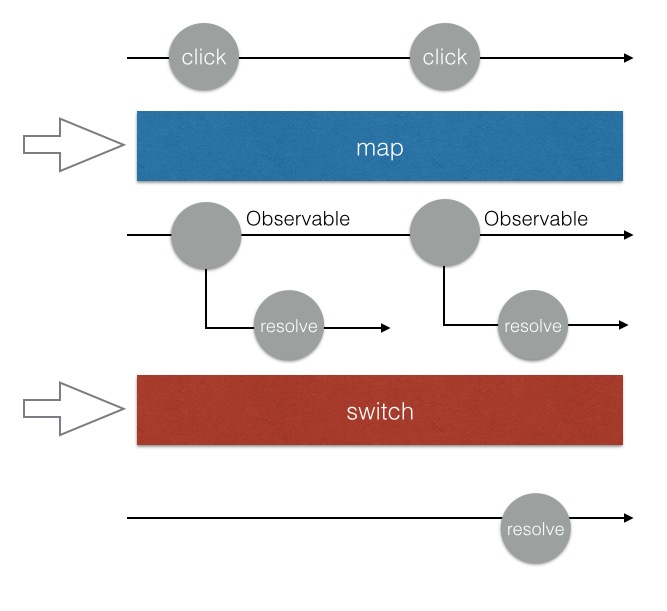
所以我們只要把flatMap改成switchMap,就可以永遠只關注最後一個發送的 request,不用去管 request 傳回來的順序,因為前面的 request 都跟這個 Observable 無關了。
Rx.Observable
.fromEvent(document.querySelector('.auto-complete input'), 'input')
.debounceTime(250)
.map(e => e.target.value)
.switchMap(value => {
return Rx.Observable.from(searchWikipedia(value)).map(res => res[1])
})
.subscribe(value => {
renderList(value);
})
做到這邊,就跟剛剛實作的功能一模一樣了。
但其實還有地方可以改進,我們來做個小小的加強好了。現在的話當我輸入abc,會出現abc的相關關鍵字,接著我把abc全部刪掉,讓 input 變成空白,會發現 API 這時候回傳一個錯誤:The "search" parameter must be set.。
因此,我們可以在 input 是空的時候,不發送 request,只回傳一個空陣列,而回傳空陣列這件事情可以用Rx.Observable.of([])來完成,這樣會創造一個會發送空陣列的 Observable:
Rx.Observable
.fromEvent(document.querySelector('.auto-complete input'), 'input')
.debounceTime(250)
.map(e => e.target.value)
.switchMap(value => {
return value.length < 1 ? Rx.Observable.of([]) : Rx.Observable.from(searchWikipedia(value)).map(res => res[1])
})
.subscribe(value => {
renderList(value);
})
還有一個點擊關鍵字清單之後把文字設定成關鍵字的功能,在這邊就不示範給大家看了,但其實就是再創造一個 Observable 去監聽點擊事件,點到的時候就設定文字並且把關鍵字清單給清掉。
我直接附上參考程式碼:
Rx.Observable
.fromEvent(document.querySelector('.auto-complete__list'), 'click')
.filter(e => e.target.matches('li'))
.map(e => e.target.innerHTML)
.subscribe(value => {
document.querySelector('.auto-complete input').value = value;
renderList([])
})
雖然我只介紹了最基本的操作,但 RxJS 的強大之處就在於除了這些,你甚至還有retry可以用,只要輕鬆加上這個,就能夠有自動重試的功能。
相關的應用場景還有很多,只要是跟 API 有關連的幾乎都可以用 RxJS 很優雅的解決。
React + Redux 的非同步解決方案:redux-observable
這是我們今天的最後一個主題了,也是我開場所提到的。
React + Redux 這一套非常常見的組合,一直都有一個問題存在,那就是沒有規範非同步行為(例如說 API)到底應該怎麼處理。而開源社群也有許多不同的解決方案,例如說 redux-thunk、redux-promise、redux-saga 等等。
我們前面講了這麼多東西,舉了這麼多範例,就是要證明給大家看 Reactive programming 很適合拿來解決複雜的非同步問題。因此,Netflix 就開源了這套redux-observable,用 RxJS 來處理非同步行為。
在瞭解 RxJS 之後,可以很輕鬆的理解redux-observable的原理。
在 redux 的應用裡面,所有的 action 都會通過 middleware,你可以在這邊對 action 做任何處理。或者我們也可以把 action 看做是一個 Observable,例如說:
Rx.Observable.from(actionStreams)
.subscribe(action => {
console.log(action.type, action.payload)
})
有了這個以後,我們就可以做一些很有趣的事情,例如說偵測到某個 action 的時候,我們就發送 request,並且把 response 放進另外一個 action 裡面送出去。
Rx.Observable.from(actionStreams)
.filter(action => action.type === 'GET_USER_INFO')
.switchMap(
action => Rx.Observable.from(API.getUserInfo(action.payload.userId))
)
.subscribe(userInfo => {
dispatch({
type: 'SET_USER_INFO',
payload: userInfo
})
})
上面就是一個簡單的例子,但其實redux-observable已經幫我們處理掉很多東西了,所以我們只要記得一個概念:
action in, action out
redux-observable 是一個 middleware,你可以在裡面加上很多epic,每一個epic就是一個 Observable,你可以監聽某一個指定的 action,做一些處理,再轉成另外一個 action。
直接看程式碼會比較好懂:
import Actions from './actions/user';
import ActionTypes from './actionTypes/user'
const getUserEpic = action$ =>
action$.ofType(actionTypes.GET_USER)
.switchMap(
action => Rx.Observable.from(API.getUserInfo(action.payload.userId))
).map(userInfo => Actions.setUsers(userInfo))
大概就是像這樣,我們監聽一個 action type(GET_USER),一接收到的時候就發送 request,並且把結果轉為setUsers這個 action,這就是所謂的 action in, action out。
這樣的好處是什麼?好處是明確制定了一個規範,當你的 component 需要資料的時候,就送出一個 get 的 action,這個 action 經過 middleware 的時候會觸發 epic,epic 發 request 給 server 拿資料,轉成另外一個 set 的 action,經過 reducer 設定資料以後更新到 component 的 props。
可以看這張流程圖:
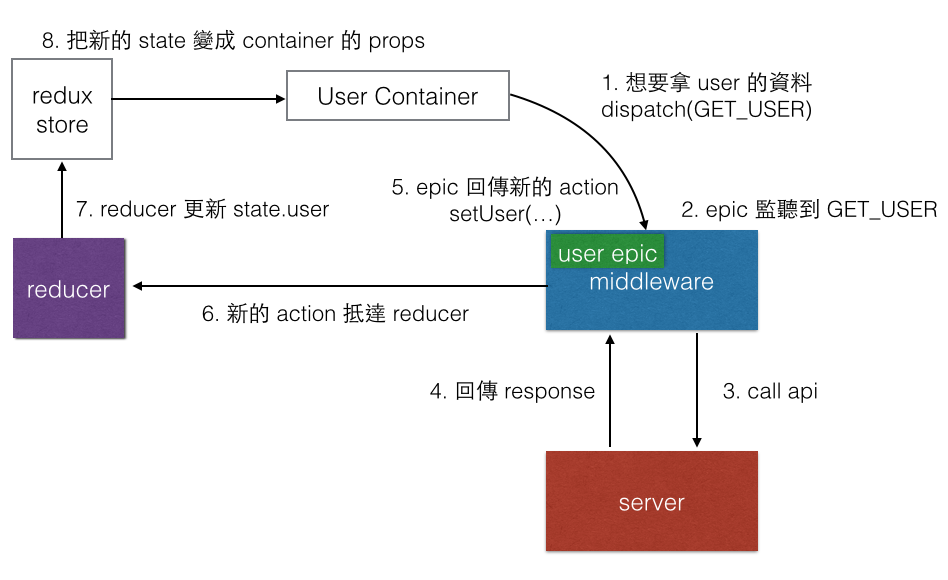
總之呢,epic就是一個 Observable,你只要確保你最後回傳的東西是一個 action 就好,那個 action 就會被送到 reducer 去。
礙於篇幅的關係,今天對於redux-observable只是概念性的帶過去而已,沒有時間好好示範,之後再來找個時間好好寫一下redux-observable的實戰應用。
結論
從一開始的陣列講到 Observable,講到畫圖的範例再講到經典的 Auto Complete,最後還講了redux-observable,這一路的過程中,希望大家有體會到 Observable 在處理非同步行為的強大之處以及簡潔。
這篇的目的是希望能讓大家理解 Observable 大概在做什麼,以及介紹一些簡單的應用場景,希望能提供一篇簡單易懂的中文入門文章,讓更多人能體會到 Observable 的威力。
喜歡這篇的話可以幫忙分享出去,發現哪邊有寫錯也歡迎留言指正,感謝。
參考資料:
30 天精通 RxJS (01):認識 RxJS
Reactive Programming 簡介與教學(以 RxJS 為例)
The introduction to Reactive Programming you’ve been missing
构建流式应用—RxJS详解
Epic Middleware in Redux
Combining multiple Http streams with RxJS Observables in Angular2
影片:
Netflix JavaScript Talks – RxJS + Redux + React = Amazing!
RxJS Quick Start with Practical Examples
RxJS Observables Crash Course
Netflix JavaScript Talks – RxJS Version 5
RxJS 5 Thinking Reactively | Ben Lesh