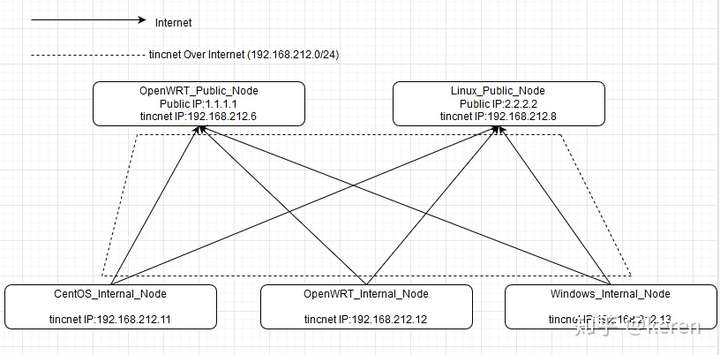
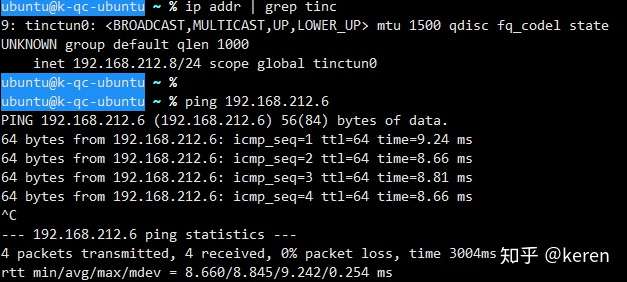
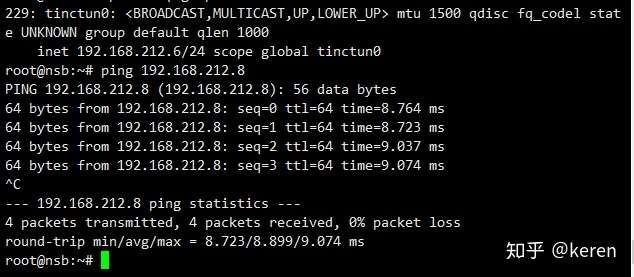
Here’s an example configuration for setting up a high availability (HA) architecture using Keepalived and Nginx:
- Install Keepalived and Nginx on each server.
- Configure Keepalived on both servers:
- Edit the Keepalived configuration file (e.g., /etc/keepalived/keepalived.conf) on each server.
- Specify the virtual IP (VIP) address that will be used for HA. For example, set
virtual_ipaddressto “192.168.0.100”. - Configure the VRRP instance with VRRP authentication and priority settings.
- Define the health check script to monitor the availability of the main server.
- Configure Nginx on each server:
- Edit the Nginx configuration file (e.g., /etc/nginx/nginx.conf) on each server.
- Define the upstream servers where the traffic will be load balanced. For example, set
upstream backendwith the IP addresses and ports of your application servers. - Configure the server block to listen on the VIP address and proxy the requests to the upstream servers.
- Start and enable Keepalived and Nginx services on both servers.
Once you have configured Keepalived and Nginx on both servers, the primary server will hold the VIP address and handle the incoming traffic. If the primary server becomes unavailable, Keepalived will automatically transfer the VIP to the secondary server, which will take over the traffic handling using Nginx.
Please note that this is a simplified example, and the actual configuration may vary based on your specific requirements and environment. It’s important to refer to the documentation and guides provided by Keepalived and Nginx to ensure a proper configuration for your HA setup.
Here’s a simplified example of a Keepalived configuration file (/etc/keepalived/keepalived.conf):
vrrp_instance VI_1 {
state MASTER # Set this to BACKUP on the secondary server
interface eth0 # Specify the network interface to monitor
virtual_router_id 51 # An arbitrary ID for the VRRP instance
priority 100 # Set this to a lower value (e.g., 90) on the secondary server
authentication {
auth_type PASS
auth_pass your_password # Set a strong password for VRRP authentication
}
virtual_ipaddress {
192.168.0.100 # The virtual IP address to be used for HA
}
track_script {
chk_nginx # Name of the health check script for monitoring Nginx
}
}
In this example, the primary server is configured as the MASTER with a higher priority, while the secondary server should be configured as BACKUP with a lower priority. The interface parameter specifies the network interface to monitor for connectivity. The virtual_router_id is an arbitrary ID used to identify the VRRP instance.
The authentication section defines the authentication method and password for VRRP. It’s important to set a strong password to ensure secure communication between the servers.
The virtual_ipaddress block specifies the virtual IP address (VIP) to be used for the HA setup. In this case, the VIP is set to 192.168.0.100.
The track_script section allows you to define the health check script (e.g., chk_nginx) that monitors the availability of Nginx.
Please note that this is a simplified example, and you may need to adjust the configuration based on your specific setup, network interface, authentication requirements, and health check script. Make sure to consult the Keepalived documentation and customize the configuration file accordingly.
Here’s a more comprehensive example of a Keepalived configuration file (/etc/keepalived/keepalived.conf) that includes additional directives:
! Configuration example for Keepalived
global_defs {
router_id HA_Cluster # An arbitrary unique identifier for the router
}
vrrp_script chk_nginx {
script "/usr/local/bin/check_nginx.sh" # Path to the custom health check script
interval 10 # Check interval in seconds
timeout 3 # Timeout in seconds
fall 3 # Number of consecutive failures to consider a server as down
rise 2 # Number of consecutive successes to consider a server as up
}
vrrp_instance VI_1 {
state MASTER # Set this to BACKUP on the secondary server
interface eth0 # Specify the network interface to monitor
virtual_router_id 51 # An arbitrary ID for the VRRP instance
priority 100 # Set this to a lower value (e.g., 90) on the secondary server
authentication {
auth_type PASS
auth_pass your_password # Set a strong password for VRRP authentication
}
virtual_ipaddress {
192.168.0.100 # The virtual IP address to be used for HA
}
track_script {
chk_nginx # Name of the health check script for monitoring Nginx
}
notify_master "/usr/local/bin/master.sh" # Path to the custom script to execute when becoming the master
notify_backup "/usr/local/bin/backup.sh" # Path to the custom script to execute when becoming the backup
notify_fault "/usr/local/bin/fault.sh" # Path to the custom script to execute on a fault event
smtp_alert # Enable email alerts in case of state transition events
smtp_server your_smtp_server # SMTP server address for email alerts
smtp_connect_timeout 30 # SMTP connection timeout in seconds
smtp_interface eth0 # Specify the network interface for email alerts
smtp_from your_email@your_domain.com # Sender email address for email alerts
smtp_to your_alert_email@your_domain.com # Recipient email address for email alerts
smtp_subject "Keepalived Notification" # Subject line for email alerts
}
In this example, the global_defs section sets a unique identifier for the router.
The vrrp_script section defines a health check script (chk_nginx) that monitors the availability of Nginx. You can replace /usr/local/bin/check_nginx.sh with the path to your custom health check script. The interval, timeout, fall, and rise parameters define the check interval, timeout, and criteria for determining the server’s state.
The vrrp_instance section configures the VRRP instance. The state parameter should be set to MASTER on the primary server and BACKUP on the secondary server. The interface parameter specifies the network interface to monitor. The virtual_router_id is an arbitrary ID used to identify the VRRP instance. The priority parameter determines the priority of the server, with a higher value indicating a higher priority.
The authentication section sets the authentication method and password for VRRP communication.
The virtual_ipaddress block specifies the virtual IP address (VIP) to be used for the HA setup.
The track_script section references the health check script to monitor Nginx availability.
The notify_master, notify_backup, and notify_fault directives specify custom scripts to execute on state transition events.
The smtp_alert directive enables email alerts for state transition events. You can configure the SMTP server and email addresses in the subsequent lines.
Please note that this configuration is provided as an example, and you will need to customize it according to your specific setup, file paths, authentication requirements, and notification scripts. Refer to the Keepalived documentation for further details on each directive and adapt the configuration to meet your needs.
Here’s an example of a Keepalived configuration file (/etc/keepalived/keepalived.conf) for the secondary server configured as BACKUP:
! Configuration example for Keepalived (BACKUP)
global_defs {
router_id HA_Cluster # An arbitrary unique identifier for the router
}
vrrp_script chk_nginx {
script "/usr/local/bin/check_nginx.sh" # Path to the custom health check script
interval 10 # Check interval in seconds
timeout 3 # Timeout in seconds
fall 3 # Number of consecutive failures to consider a server as down
rise 2 # Number of consecutive successes to consider a server as up
}
vrrp_instance VI_1 {
state BACKUP # Set this to MASTER on the primary server
interface eth0 # Specify the network interface to monitor
virtual_router_id 51 # An arbitrary ID for the VRRP instance
priority 90 # Set this to a higher value (e.g., 100) on the primary server
authentication {
auth_type PASS
auth_pass your_password # Set the same strong password used on the primary server
}
virtual_ipaddress {
192.168.0.100 # The virtual IP address to be used for HA
}
track_script {
chk_nginx # Name of the health check script for monitoring Nginx
}
notify_master "/usr/local/bin/master.sh" # Path to the custom script to execute when becoming the master
notify_backup "/usr/local/bin/backup.sh" # Path to the custom script to execute when becoming the backup
notify_fault "/usr/local/bin/fault.sh" # Path to the custom script to execute on a fault event
smtp_alert # Enable email alerts in case of state transition events
smtp_server your_smtp_server # SMTP server address for email alerts
smtp_connect_timeout 30 # SMTP connection timeout in seconds
smtp_interface eth0 # Specify the network interface for email alerts
smtp_from your_email@your_domain.com # Sender email address for email alerts
smtp_to your_alert_email@your_domain.com # Recipient email address for email alerts
smtp_subject "Keepalived Notification" # Subject line for email alerts
}The /usr/local/bin/master.sh script mentioned in the Keepalived configuration file is a custom script that you can create and define according to your specific requirements when the server becomes the master in the high availability setup. This script allows you to perform any necessary actions or configurations when the server transitions to the master state.
Here’s an example of a simple /usr/local/bin/master.sh script:
#!/bin/bash
# This script is executed when the server becomes the master in the high availability setup
# Add your custom actions or configurations here
echo "Server is now the master. Performing custom actions..."
# Example: Start additional services or update configurations
# Restart Nginx to ensure it's using the VIP
systemctl restart nginx
In this example, the script starts by printing a message indicating that the server is now the master and then proceeds to perform any necessary custom actions or configurations. You can add your own logic to the script, such as starting additional services, updating configurations, or performing any other tasks required when the server becomes the master.
In this specific example, the script restarts Nginx to ensure that it is using the virtual IP (VIP) address, which is now assigned to the master server.
Remember to make the script executable by running the following command:
chmod +x /usr/local/bin/master.sh
You can modify the /usr/local/bin/master.sh script according to your specific needs and include any additional commands or configurations that are relevant to your high availability setup.
The /usr/local/bin/check_nginx.sh script mentioned in the Keepalived configuration file is a custom health check script that monitors the availability of Nginx. This script is executed periodically by Keepalived to determine the state of the server and make decisions based on the health check results.
Here’s an example of a simple /usr/local/bin/check_nginx.sh script:
#!/bin/bash
# This script checks the availability of Nginx
# Perform a health check on Nginx
response=$(curl -s -o /dev/null -w "%{http_code}" http://localhost)
# Check the HTTP response code
if [ "$response" = "200" ]; then
exit 0 # Nginx is healthy, exit with 0 (success)
else
exit 1 # Nginx is down or not responding properly, exit with 1 (failure)
fi
In this example, the script uses the curl command to send a request to http://localhost and retrieves the HTTP response code. If the response code is 200 (indicating a successful response), the script exits with a status of 0, indicating that Nginx is healthy. Otherwise, if the response code is different from 200, the script exits with a status of 1, indicating that Nginx is down or not responding properly.
You can customize the health check script according to your specific requirements and the way you want to check the health of Nginx. For example, you may want to check additional conditions, such as the response time, specific content on the page, or perform more complex checks. Adapt the script to suit your needs and ensure that it exits with a status of 0 (success) when Nginx is healthy and 1 (failure) when Nginx is down or not responding as expected.
Don’t forget to make the script executable by running the following command:
chmod +x /usr/local/bin/check_nginx.sh
This allows Keepalived to execute the script and perform the health checks at the specified interval in the configuration file.
The /usr/local/bin/backup.sh script mentioned in the Keepalived configuration file is a custom script that you can create and define according to your specific requirements when the server transitions to the backup state in the high availability setup. This script allows you to perform any necessary actions or configurations on the backup server.
Here’s an example of a simple /usr/local/bin/backup.sh script:
#!/bin/bash
# This script is executed when the server becomes the backup in the high availability setup
# Add your custom actions or configurations here
echo "Server is now the backup. Performing custom actions..."
# Example: Stop unnecessary services or disable certain functionalities
# Stop Nginx to prevent conflicts with the master server
systemctl stop nginx
In this example, the script starts by printing a message indicating that the server is now the backup and then proceeds to perform any necessary custom actions or configurations. You can add your own logic to the script, such as stopping unnecessary services, disabling certain functionalities, or performing any other tasks required when the server transitions to the backup state.
In this specific example, the script stops Nginx to prevent conflicts with the master server since the backup server should not be actively serving traffic while in the backup state.
Remember to make the script executable by running the following command:
chmod +x /usr/local/bin/backup.sh
You can modify the /usr/local/bin/backup.sh script according to your specific needs and include any additional commands or configurations that are relevant to your high availability setup.
The /usr/local/bin/fault.sh script mentioned in the Keepalived configuration file is a custom script that you can create and define according to your specific requirements to handle fault events in the high availability setup. This script is executed when a fault event occurs, indicating a problem with the server or the high availability configuration.
Here’s an example of a simple /usr/local/bin/fault.sh script:
#!/bin/bash
# This script is executed on a fault event in the high availability setup
# Add your custom actions or configurations here
echo "Fault event detected. Performing custom actions..."
# Example: Send notifications, log the event, or trigger failover procedures
# Restart Keepalived to initiate failover
systemctl restart keepalived
In this example, the script starts by printing a message indicating that a fault event has been detected and then proceeds to perform any necessary custom actions or configurations. You can add your own logic to the script, such as sending notifications, logging the event, triggering failover procedures, or performing any other tasks required when a fault event occurs.
In this specific example, the script restarts Keepalived to initiate a failover procedure. Restarting Keepalived can help recover from certain types of faults and trigger the transition to a new master server if necessary.
Remember to make the script executable by running the following command:
chmod +x /usr/local/bin/fault.sh
You can modify the /usr/local/bin/fault.sh script according to your specific needs and include any additional commands or configurations that are relevant to handling fault events in your high availability setup.