—-BEGIN LICENSE—–
TNT Team
Unlimited User License
EA7E-2010859462
6C5E525261BC8146AAAC8783279A74F5
57BF1CB0C1944B5517D42C38DB2282F2
E047071E334FEF878FFF09A3BB2B787B
06CE14F6DDAFB7A8C1123C226C250323
B45CC6567A2575668B94A3ACB773D963
ED045D9F798CC023694AF1467FD51C75
B05B81C8B226863915DC1140ADB97EC4
1CFA3B0FD72AACB8DBA7B6204A7AC4C2
—–END LICENSE—–
DBeaver Ultimate 22.1 旗舰版激活方法
本站惯例:本文假定你知道DBeaver。不知道可以问问搜索引擎。
DBeaver是一款优秀的数据库管理工具,支持管理众多数据库产品,巴拉巴拉。
DBeaver Ultimate(简称DBeaverUE)支持MongoDB、Redis、Apache Hive等,对比于DBeaver Enterprise多了连接云服务器的功能,但是需要付费使用。
这次要送的这份礼就是: DBeaverUE 22.1.0及以下版本(理论上适用于目前所有新老版本)的破解,可使用它来激活你手头上的DBeaverUE。
下载地址:
百度云下载(download link),提取码:hvx1。
OneDrive(download link)
具体使用方法已写在压缩包的README.txt内,有什么问题可以给我提Issue或进QQ群:30347511讨论。
按照README.txt配置好之后,使用DBeaverUE专用激活码:
1 2 3 4 5 |
aYhAFjjtp3uQZmeLzF3S4H6eTbOgmru0jxYErPCvgmkhkn0D8N2yY6ULK8oT3fnpoEu7GPny7csN sXL1g+D+8xR++/L8ePsVLUj4du5AMZORr2xGaGKG2rXa3NEoIiEAHSp4a6cQgMMbIspeOy7dYWX6 99Fhtpnu1YBoTmoJPaHBuwHDiOQQk5nXCPflrhA7lldA8TZ3dSUsj4Sr8CqBQeS+2E32xwSniymK 7fKcVX75qnuxhn7vUY7YL2UY7EKeN/AZ+1NIB6umKUODyOAFIc8q6zZT8b9aXqXVzwLJZxHbEgcO 8lsQfyvqUgqD6clzvFry9+JwuQsXN0wW26KDQA== |
DBeaverUE有几点需要注意的:
- windows 系统请使用
ZIP包,下载链接:x64 - mac 系统请使用
DMG包,下载链接:intel / m1 - linux 系统请使用
.TAR.GZ包,下载链接:x64 - DBeaver运行需要
java,请自行安装! - 不要使用DBeaver自带的
jre,它被人为阉割了。
22.1版本请在dbeaver.ini文件末尾添加一行:-Dlm.debug.mode=true
请自行安装jdk11,替换dbeaver.ini内由-vm指定的java路径,把地址换成自己安装的!
如果你的dbeaver.ini内没有-vm参数,请在首行添加你安装jdk的java路径:
1 2 |
-vm /path/to/your/bin/java |
下面是国际惯例:
本项目只做个人学习研究之用,不得用于商业用途!
若资金允许,请购买正版,谢谢合作!
- 本文链接: https://zhile.io/2019/05/09/dbeaver-ue-license-crack.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!
Spring Boot Admin的介绍及使用
Spring Boot 有一个非常好用的监控和管理的源软件,这个软件就是 Spring Boot Admin。该软件能够将 Actuator 中的信息进行界面化的展示,也可以监控所有 Spring Boot 应用的健康状况,提供实时警报功能。
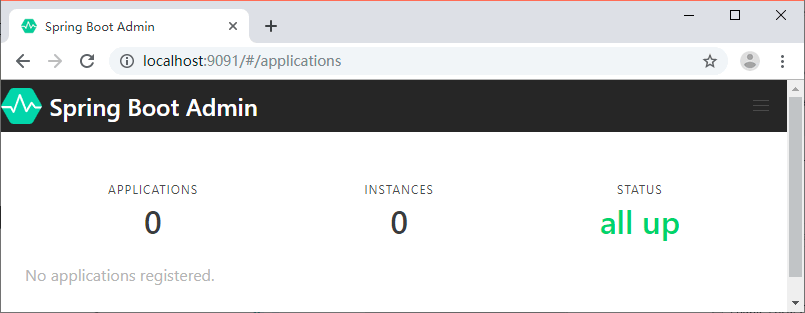
图 1 Spring Boot Admin主页
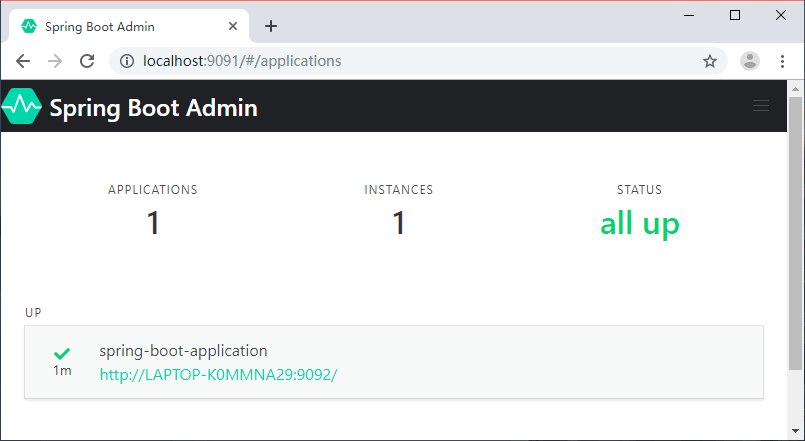
图 2 Spring Boot Admin主页(有数据)
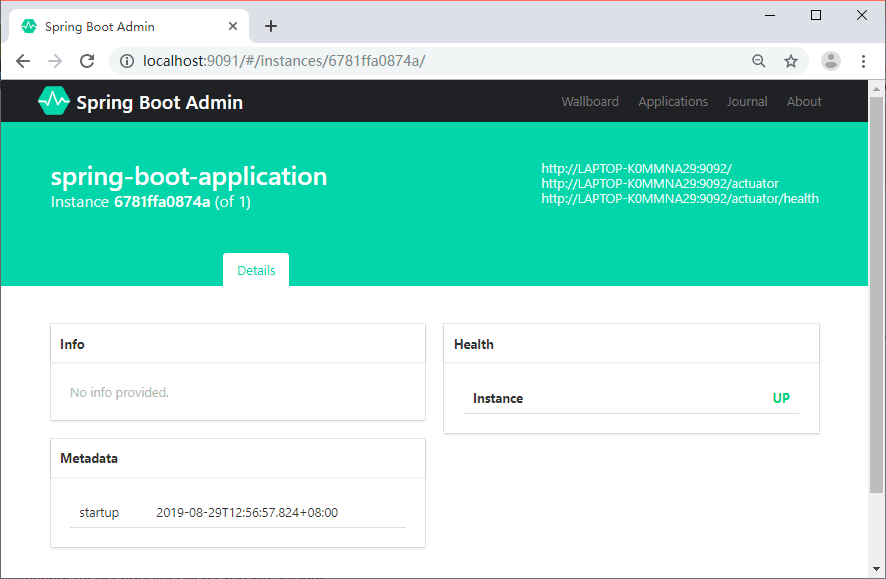
图 3 Spring Boot Admin详情
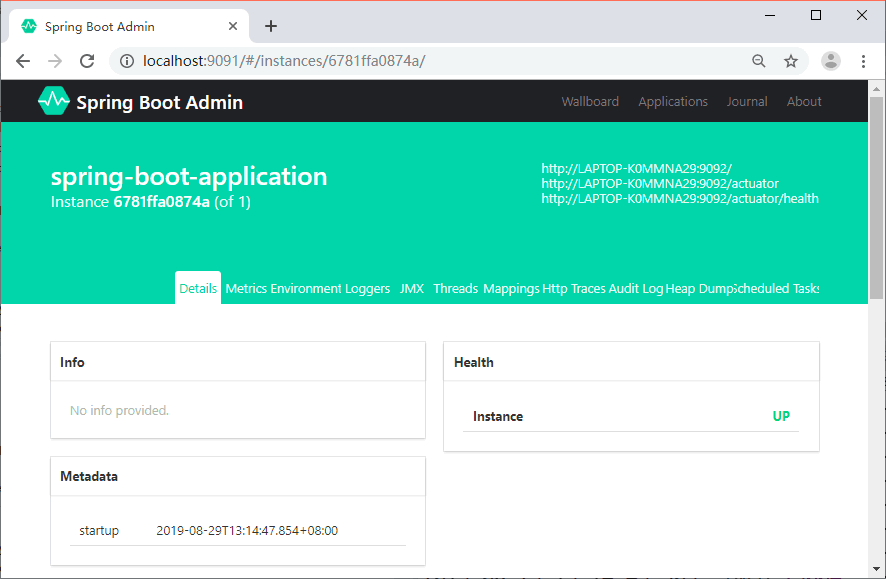
图 4 Spring Boot Admin详情(有数据)
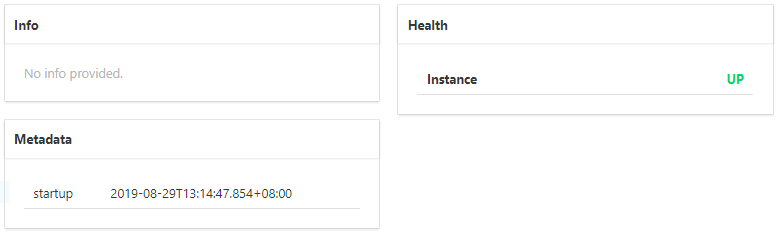
图 5 Spring Boot Admin数据展示(一)
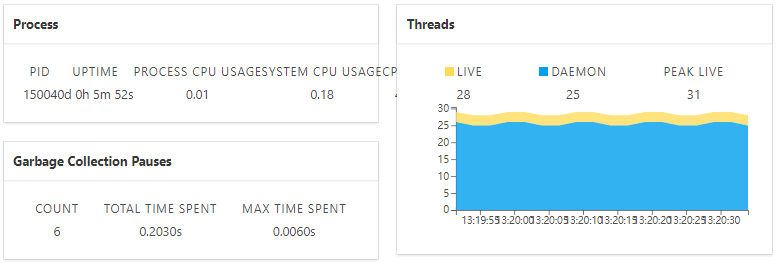
图 6 Spring Boot Admin数据展示(二)
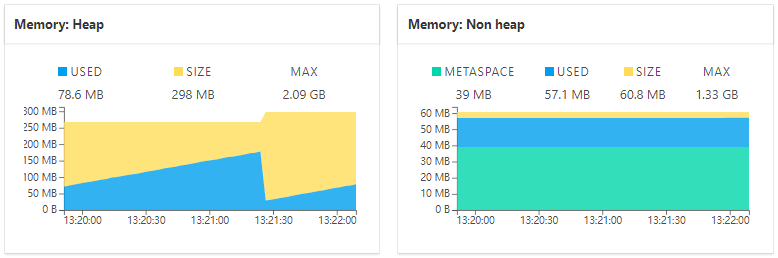
图 7 Spring Boot Admin数据展示(三)
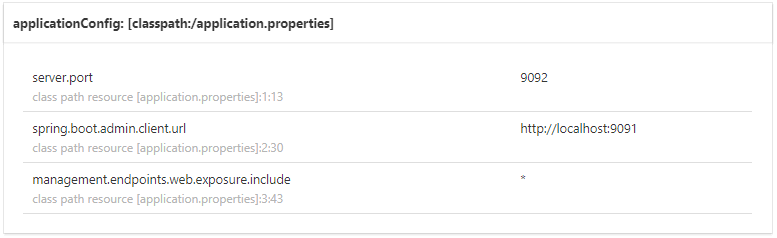
图 8 Spring Boot Admin数据展示(四)
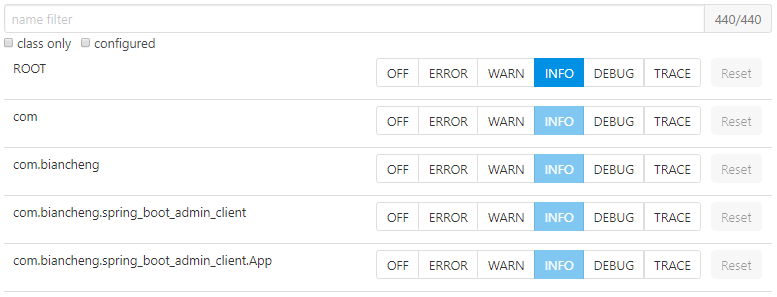
图 9 Spring Boot Admin数据展示(五)
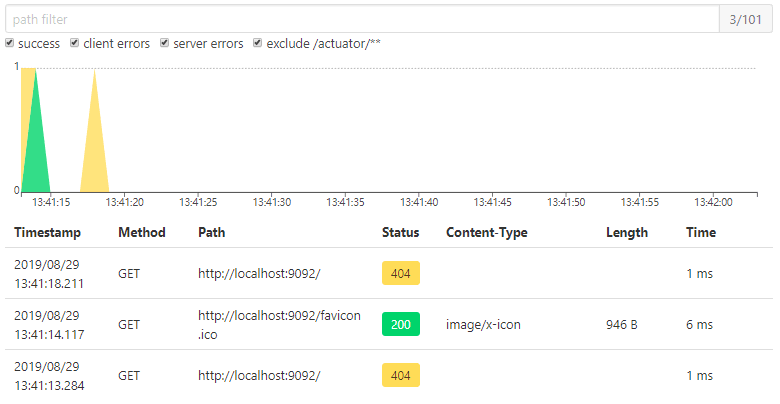
图 10 Spring Boot Admin数据展示(六)
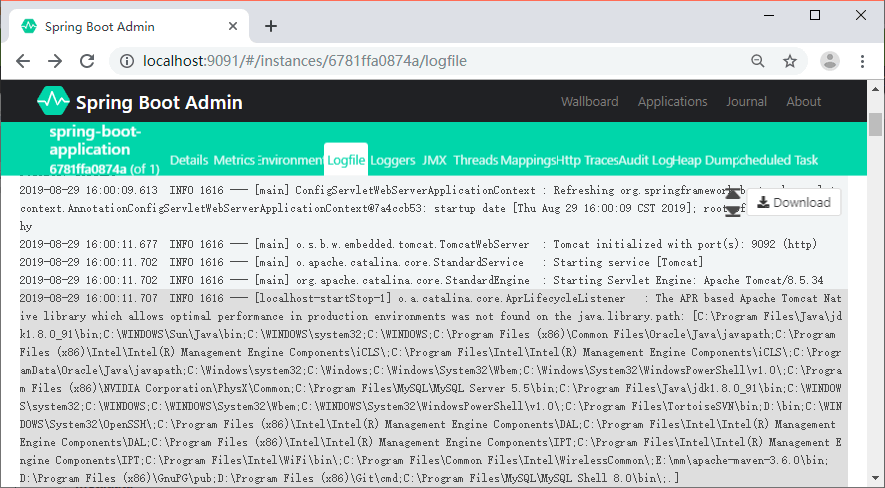
图 11 Spring Boot Admin 日志
主要的功能点有:
- 显示应用程序的监控状态
- 应用程序上下线监控
- 查看 JVM,线程信息
- 可视化的查看日志以及下载日志文件
- 动态切换日志级别
- Http 请求信息跟踪
- 其他功能点……
可点击 https://github.com/codecentric/spring-boot-admin 更多了解 Spring-boot-admin。
创建Spring Boot Admin项目
创建一个 Spring Boot 项目,用于展示各个服务中的监控信息,加上 Spring Boot Admin 的依赖,具体代码如下所示。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>2.0.2</version>
</dependency>
创建一个启动类,具体代码如下所示。
- @EnableAdminServer
- @SpringBootApplication
- public class App {
- public static void main(String[] args) {
- SpringApplication.run(App.class, args);
- }
- }
在属性文件中增加端口配置信息:
server.port=9091
启动程序,访问 Web 地址 http://localhost:9091 就可以看到主页面了,这个时候是没有数据的,如图 1 所示。
图 1 Spring Boot Admin主页
将服务注册到 Spring Boot Admin
创建一个 Spring Boot 项目,名称为 spring-boot-admin-client。添加 Spring Boot Admin Client 的 Maven 依赖,代码如下所示。
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-client</artifactId>
<version>2.0.2</version>
</dependency>
然后在属性文件中添加下面的配置:
server.port=9092
spring.boot.admin.client.url=http://localhost:9091
spring.boot.admin.client.url:Spring Boot Admin 服务端地址。
将服务注册到 Admin 之后我们就可以在 Admin 的 Web 页面中看到我们注册的服务信息了,如图 2 所示。
图 2 Spring Boot Admin主页(有数据)
点击实例信息跳转到详细页面,可以查看更多的信息,如图 3 所示。
图 3 Spring Boot Admin详情
可以看到详情页面并没有展示丰富的监控数据,这是因为没有将 spring-boot-admin-client 的端点数据暴露出来。
在 spring-boot-admin-client 中加入 actuator 的 Maven 依赖,代码如下所示。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然后在属性文件中追加下面的配置:
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.include:暴露所有的 actuator 端点信息重启 spring-boot-admin-client,我们就可以在详情页面看到更多的数据,如图 4 所示。
图 4 Spring Boot Admin详情(有数据)
监控内容介绍
自定义的 Info 信息、健康状态、元数据,如图 5 所示。
图 5 Spring Boot Admin数据展示(一)
CPU、线程等信息如图 6 所示。
图 6 Spring Boot Admin数据展示(二)
内存使用情况如图 7 所示。
图 7 Spring Boot Admin数据展示(三)
配置信息如图 8 所示。
图 8 Spring Boot Admin数据展示(四)
日志级别调整如图 9 所示。
图 9 Spring Boot Admin数据展示(五)
Http请求信息如图 10 所示。
图 10 Spring Boot Admin数据展示(六)
如何在Admin中查看各个服务的日志
Spring Boot Admin 提供了基于 Web 页面的方式实时查看服务输出的本地日志,前提是服务中配置了 logging.file。
我们在 spring-boot-admin-client 的属性文件中增加下面的内容:
logging.file=/Users/zhangsan/Downloads/spring-boot-admin-client.log
重启服务,就可以在 Admin Server 的 Web 页面中看到新加了一个 Logfile 菜单,如图 11 所示。
图 11 Spring Boot Admin 日志
Docker Dockerfile
什么是 Dockerfile?
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
使用 Dockerfile 定制镜像
这里仅讲解如何运行 Dockerfile 文件来定制一个镜像,具体 Dockerfile 文件内指令详解,将在下一节中介绍,这里你只要知道构建的流程即可。
1、下面以定制一个 nginx 镜像(构建好的镜像内会有一个 /usr/share/nginx/html/index.html 文件)
在一个空目录下,新建一个名为 Dockerfile 文件,并在文件内添加以下内容:
FROM nginx
RUN echo ‘这是一个本地构建的nginx镜像’ > /usr/share/nginx/html/index.html
2、FROM 和 RUN 指令的作用
FROM:定制的镜像都是基于 FROM 的镜像,这里的 nginx 就是定制需要的基础镜像。后续的操作都是基于 nginx。
RUN:用于执行后面跟着的命令行命令。有以下俩种格式:
shell 格式:
RUN <命令行命令>
# <命令行命令> 等同于,在终端操作的 shell 命令。
exec 格式:
RUN [“可执行文件”, “参数1”, “参数2”]
# 例如:
# RUN [“./test.php”, “dev”, “offline”] 等价于 RUN ./test.php dev offline
注意:Dockerfile 的指令每执行一次都会在 docker 上新建一层。所以过多无意义的层,会造成镜像膨胀过大。例如:
FROM centos
RUN yum -y install wget
RUN wget -O redis.tar.gz “http://download.redis.io/releases/redis-5.0.3.tar.gz”
RUN tar -xvf redis.tar.gz
以上执行会创建 3 层镜像。可简化为以下格式:
FROM centos
RUN yum -y install wget \
&& wget -O redis.tar.gz “http://download.redis.io/releases/redis-5.0.3.tar.gz” \
&& tar -xvf redis.tar.gz
如上,以 && 符号连接命令,这样执行后,只会创建 1 层镜像。
开始构建镜像
在 Dockerfile 文件的存放目录下,执行构建动作。
以下示例,通过目录下的 Dockerfile 构建一个 nginx:v3(镜像名称:镜像标签)。
注:最后的 . 代表本次执行的上下文路径,下一节会介绍。
$ docker build -t nginx:v3 .
以上显示,说明已经构建成功。
上下文路径
上一节中,有提到指令最后一个 . 是上下文路径,那么什么是上下文路径呢?
$ docker build -t nginx:v3 .
上下文路径,是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。
解析:由于 docker 的运行模式是 C/S。我们本机是 C,docker 引擎是 S。实际的构建过程是在 docker 引擎下完成的,所以这个时候无法用到我们本机的文件。这就需要把我们本机的指定目录下的文件一起打包提供给 docker 引擎使用。
如果未说明最后一个参数,那么默认上下文路径就是 Dockerfile 所在的位置。
注意:上下文路径下不要放无用的文件,因为会一起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。
指令详解
COPY
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
格式:
COPY [–chown=:] <源路径1>… <目标路径>
COPY [–chown=:] [“<源路径1>”,… “<目标路径>”]
[–chown=:]:可选参数,用户改变复制到容器内文件的拥有者和属组。
<源路径>:源文件或者源目录,这里可以是通配符表达式,其通配符规则要满足 Go 的 filepath.Match 规则。例如:
COPY hom* /mydir/
COPY hom?.txt /mydir/
<目标路径>:容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。
ADD
ADD 指令和 COPY 的使用格类似(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
CMD 在docker run 时运行。
RUN 是在 docker build。
作用:为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
注意:如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
格式:
CMD
CMD [“<可执行文件或命令>”,””,””,…]
CMD [“”,””,…] # 该写法是为 ENTRYPOINT 指令指定的程序提供默认参数
推荐使用第二种格式,执行过程比较明确。第一种格式实际上在运行的过程中也会自动转换成第二种格式运行,并且默认可执行文件是 sh。
ENTRYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 –entrypoint 选项,将覆盖 ENTRYPOINT 指令指定的程序。
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
格式:
ENTRYPOINT [“”,””,””,…]
可以搭配 CMD 命令使用:一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参,以下示例会提到。
示例:
假设已通过 Dockerfile 构建了 nginx:test 镜像:
FROM nginx
ENTRYPOINT [“nginx”, “-c”] # 定参
CMD [“/etc/nginx/nginx.conf”] # 变参
1、不传参运行
$ docker run nginx:test
容器内会默认运行以下命令,启动主进程。
nginx -c /etc/nginx/nginx.conf
2、传参运行
$ docker run nginx:test -c /etc/nginx/new.conf
容器内会默认运行以下命令,启动主进程(/etc/nginx/new.conf:假设容器内已有此文件)
nginx -c /etc/nginx/new.conf
ENV
设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
格式:
ENV
ENV = =…
以下示例设置 NODE_VERSION = 7.2.0 , 在后续的指令中可以通过 $NODE_VERSION 引用:
ENV NODE_VERSION 7.2.0
RUN curl -SLO “https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.xz” \
&& curl -SLO “https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc”
ARG
构建参数,与 ENV 作用一致。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
构建命令 docker build 中可以用 –build-arg <参数名>=<值> 来覆盖。
格式:
ARG <参数名>[=<默认值>]
VOLUME
定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
避免重要的数据,因容器重启而丢失,这是非常致命的。
避免容器不断变大。
格式:
VOLUME [“<路径1>”, “<路径2>”…]
VOLUME <路径>
在启动容器 docker run 的时候,我们可以通过 -v 参数修改挂载点。
EXPOSE
仅仅只是声明端口。
作用:
帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。
在运行时使用随机端口映射时,也就是 docker run -P 时,会自动随机映射 EXPOSE 的端口。
格式:
EXPOSE <端口1> [<端口2>…]
WORKDIR
指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。(WORKDIR 指定的工作目录,必须是提前创建好的)。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。
格式:
WORKDIR <工作目录路径>
USER
用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
格式:
USER <用户名>[:<用户组>]
HEALTHCHECK
用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK [选项] CMD <命令> : 这边 CMD 后面跟随的命令使用,可以参考 CMD 的用法。
ONBUILD
用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
格式:
ONBUILD <其它指令>
LABEL
LABEL 指令用来给镜像添加一些元数据(metadata),以键值对的形式,语法格式如下:
LABEL = = = …
比如我们可以添加镜像的作者:
LABEL org.opencontainers.image.authors=”StrongYuen”
OpenWRT下安装和配置shadowsocks
Environment
- 路由器型号:YouHua WR1200JS
- 固件版本:OpenWrt 19.07.4 r11208-ce6496d796 / LuCI openwrt-19.07 branch git-21.054.03371-3b137b5
拓扑图+工作原理

- dnsmasq是openwrt自带的一个软件,提供dns缓存,dhcp等功能。dnsmasq会将dns查询数据包转发给chinadns。
- chinadns的上游DNS服务器有两个,一个是
国内DNS,一个是可信DNS(国外DNS)。- chinadns会同时向上游的DNS发送请求
- 如果
可信DNS先返回, 则直接采用可信DNS的结果 - 如果
国内DNS先返回, 分两种情况: 如果返回的结果是国内IP,则采用;否则丢弃并等待采用可信DNS的结果
3.dns-forwarder 支持DNS TCP查询, 如果ISP的UDP不稳定, 丢包严重,可以使用dns-forwarder来代替ss-tunnel来进行DNS查询.
4.shadowsocks 用于转发数据包, 科学上网. 关于shadowsocks的科普文章可查看这里: https://www.css3er.com/p/107.html
相关的ipk软件包下载地址
ipk软件包集合, 不同的CPU架构需要使用不同的软件包, CPU架构是mipsel_24kc的话, 可以集中从这里下载.
链接: https://pan.baidu.com/s/14QDoTLqw-SEBZvQVQeVgvA 提取码: ugsc
其它的CPU架构, 可以去GitHub主页 -> Releases下载别人已经编译好的软件包, 如果没有, 只能自己下载openWRT的SDK, 自己进行编译.
- shadowsocks-libev_3.3.5-1_mipsel_24kc.ipk
- shadowsocks-libev-server_3.3.5-1_mipsel_24kc.ipk
- ChinaDNS_1.3.3-1_mipsel_24kc.ipk
- dns-forwarder_1.2.1-2_mipsel_24kc.ipk
- luci-compat
- luci-app-shadowsocks-without-ipset_1.9.1-1_all.ipk
- luci-app-chinadns_1.6.2-1_all.ipk
- luci-app-dns-forwarder_1.6.2-1_all.ipk
链接: https://pan.baidu.com/s/14QDoTLqw-SEBZvQVQeVgvA 提取码: ugsc
openwrt-shadowsocks
GitHub: https://github.com/shadowsocks/openwrt-shadowsocks
luci-app-shadowsocks: https://github.com/shadowsocks/luci-app-shadowsocks
- shadowsocks-libev
客户端/ └── usr/ └── bin/ ├── ss-local // 提供 SOCKS 正向代理, 在透明代理工作模式下用不到这个. ├── ss-redir // 提供透明代理, 从 v2.2.0 开始支持 UDP └── ss-tunnel // 提供端口转发, 可用于 DNS 查询 - shadowsocks-libev-server
服务端/ └── usr/ └── bin/ └── ss-server // 服务端可执行文件
ChinaDNS
GitHub: https://github.com/aa65535/openwrt-chinadns
原版ChinaDNS地址, 被请喝茶后已不再维护:https://github.com/shadowsocks/ChinaDNS
luci-app-chinadns: https://github.com/aa65535/openwrt-dist-luci
更新 /etc/chinadns_chnroute.txt
1
|
|
dns-forwarder
GitHub: https://github.com/aa65535/openwrt-dns-forwarder
luci-app-dns-forwarder: https://github.com/aa65535/openwrt-dist-luci
dnsmasq
openWRT自带, 无需自行下载安装.
GitHub: https://github.com/aa65535/openwrt-dnsmasq
Install
去软件项目的GitHub主页 -> Releases下面下载编译好的ipk, 如果没有符合的自己CPU架构的包, 则需要自己下载openWRT的SDK进行编译, 具体的教程各个主页上有.
查看CPU架构的命令 opkg print-architecture:
1 2 3 4 5 |
|
下载完成有两种方式安装
方式一(建议): 通过web使用luci安装: 路径: 系统 -> Software -> Upload Package… -> Install
方式二: 直接在线通过opkg命令来安装(注意使用方式需要提前更新好软件源, opkg update):
1
|
|
Config
方式一, 使用luci来配置
登录luci.
- 配置ss-server
服务->影梭->服务器管理, 添加自己的shadowsocks server - 配置dnsmasq
网络->DHCP/DNS->常规设置->本地服务器, 设置为127.0.0.1#5353网络->DHCP/DNS->HOSTS和解析文件, 勾选:忽略解析文件
- 配置ChinaDNS
服务->ChinaDNS
监听端口:5353
上游服务器修改为:114.114.114.114,127.0.0.1#5300
这样国内DNS:114.114.114.114,可信DNS:127.0.0.1#5353, 勾选启用, 保存设置 - 配置dns-forwarder
服务->DNS转发
监听端口:5300监听地址:0.0.0.0
上游 DNS:8.8.8.8勾选,启用保存 - 配置shadowsocks 透明代理 + 访问控制
服务->影梭->常规设置->透明代理
主服务器, 选择setp1中配置的ss-server, 保存.
服务->影梭->常规设置->访问控制->外网区域
被忽略IP列表, 选择ChinaDNS路由表, 保存设置. 注意这里的优先级: (走代理IP列表 = 强制走代理IP) > (额外被忽略IP = 被忽略IP列表) 保存并应用所有配置, reboot openWRT
方式二, 直接编辑/etc/config目录下的文件
课外阅读: UCI System UCI system
The abbreviation UCI stands for Unified Configuration Interface and is intended to centralize the configuration of OpenWrt.
/etc/config/shadowsocks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
/etc/config/dhcp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
/etc/config/chinadns
1 2 3 4 5 6 7 8 9 |
|
/etc/config/dns-forwarder
1 2 3 4 5 6 7 |
|
验证配置是否生效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
Issues
- luci-app-shadowsocks 不支持domain的方式配置ss-server, 需要使用IP地址
Link
https://www.youtube.com/watch?v=2SPQYsMmltE&t=317s – 十年老程 openwrt shadowsocks安装配置对应的视频教程 http://snlcw.com/305.html – 上述教程对应的blog地址. https://www.youtube.com/channel/UCgo7XWK6MQBgKt0gBI6x3CA/videos – 十年老程的Youtube专栏,里面有各种科学上网的视频教程. https://openwrt.org/docs/guide-user/base-system/dhcp_configuration
penWRT 结合 tinc 组自己的 SDLAN(Step by Step)
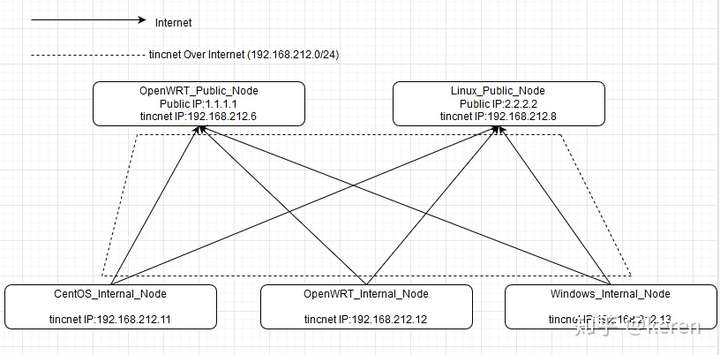
本文主要实现在OpenWRT路由器以及不同系统下通过tinc switch mode搭建SDLAN内网服务器方便远程连接,
Switch Mode相对来说配置比较简单,各节点均在同一广播域内,方便调控,tinc节点本身通过DNAT+SNAT可以实现对不同网间端口的调通,
同时Switch Mode中各节点的hosts文件只需保证在公网地址的节点中全部拥有维护即可,其他节点只需维护本节点以及公网节点的hosts文件
下面主要分三步:
(1)公网节点的部署(Master节点)
(2)其他节点的部署(Slave节点)
(3)节点的NAT配置
本次搭建的拓扑以下为例,两个Master节点,若干个Slave节点(以3个不同操作系统的为例)
(0)tinc的安装
各大Linux发行版基本都可以通过包管理对tinc进行安装
sudo yum install tinc
sudo apt install tinc OpenWRT也可通过opkg安装tinc
opkg update
opkg install tincWindows可在官网下载
Windows中自带的TAP-Windwos版本比较低,建议可以考虑另外安装版本较新的TAP-Windows新建虚拟网卡而不是用tinc-vpn安装包中自带的TAP-Windows
(1)公网节点的部署(Master节点)
需要预先定义定义一个网络名 本次以tincnet为例NETNAME = tincnet
每个节点均需要以以下目录结构创建好配置文件夹
/etc/tinc/tincnet
% ls -la
total 24
drwxr-xr-x 3 root root 4096 Mar 4 15:07 .
drwxr-xr-x 4 root root 4096 Mar 4 15:06 ..
drwxr-xr-x 2 root root 4096 Mar 4 15:06 hosts
-rwxr-xr-x 1 root root 198 Mar 4 15:06 tinc.conf
-rwxr-xr-x 1 root root 72 Mar 4 15:06 tinc-down
-rwxr-xr-x 1 root root 81 Mar 4 15:06 tinc-uptinc.conf为tinc的配置文件,tinc-down,tinc-up为启动tinc时执行的脚本,一般用作启动网络,hosts文件夹中存的是各个结点的连接交换信息。
下面先说其中一个节点Linux_Public_Node(2.2.2.2)
各个文件配置情况:
tinc.conf
% cat tinc.conf
Name = Linux_Public_Node #此节点名称为Linux_Public_Node
AddressFamily = ipv4 #Internet走IPv4协议
BindToAddress = * 11001 #监听端口
Interface = tinctun0 #tincnet虚拟网卡
Device = /dev/net/tun
#Mode = <router|switch|hub> (router)
Mode = switch #设置使用Swtich模式 默认为router
ConnectTo = OpenWRT_Public_Node #连接另一公网Master节点保持双活
Cipher = aes-128-cbc #对称加密算法tinc-up tinc启动脚本,给对应网卡加IP
% cat tinc-up
#!/bin/sh
ip link set $INTERFACE up
ip addr add 192.168.212.8/24 dev $INTERFACEtinc-down tinc停止脚本,关停对应网卡
#!/bin/sh
ip addr del 192.168.212.8/24 dev $INTERFACE
ip link set $INTERFACE downhosts文件夹 主要保存各节点的交换信息,由于是第一次创建,里面应该是空文件夹,需要先创建一个自己节点的链接信息
cd hosts
touch Linux_Public_Node % cat Linux_Public_Node
Address = 2.2.2.2 #公网地址
Subnet = 192.168.212.8/32 #tincnetIP信息
Port = 11001 #公网监听端口创建完成后通过tincd生成非对称密钥信息
% sudo tincd -n tincnet -K
Generating 2048 bits keys:
.............+++++ p
........................+++++ q
Done.
Please enter a file to save private RSA key to [/etc/tinc/tincnet/rsa_key.priv]:
Please enter a file to save public RSA key to [/etc/tinc/tincnet/hosts/Linux_Public_Node]: 现在tincnet文件夹中会生成私钥,对应的公钥信息会补全到host/Linux_Public_Node中
% ls /etc/tinc/tincnet
hosts rsa_key.priv tinc.conf tinc-down tinc-up
% cat /etc/tinc/tincnet/hosts/Linux_Public_Node
Address = 2.2.2.2
Subnet = 192.168.212.8/32
Port = 11001
-----BEGIN RSA PUBLIC KEY-----
MIIBCgKCAQEAp7F+8s8lukRv0qaE5hzrQmuy2MPb8hlte/G0pcfnBCVjIL5foJ7P
LZQrTGTsKjRbPzJ9gfZUXiZRkaA+G6Q4DBOVEt41cTceZTgAzL3ief3H6MNXQ0xW
1Wo8kDNlg6g+QJq8iV5j7adJnEPivrDm4CWl8MRmVOckisnQbseKXeuzIYDhpZLA
nlIIGMzhk3OZoPn2xpdMbJqbR0K6SrPvYq7sT3eLn0NVUbyo9D1dmtwtOJy8wmaf
oYdwTvrMdXhNNUmemnswJt8T2j8rAerqnjqz5itN8dk9mZMTKLFZ44CNnJ8jl5pE
ma8lfUnAA/Qq7i9t74pVEvWcLg8HIry16QIDAQAB
-----END RSA PUBLIC KEY-----至此,节点Linux_Public_Node(2.2.2.2)中的配置已经完成,
下面配置另外一个节点OpenWRT_Public_Node(1.1.1.1)
主要的配置文件生成过程节点Linux_Public_Node类似
生成后如下:
ls -la /etc/tinc/tincnet/
drwxr-xr-x 3 root root 4096 Mar 4 15:32 .
drwxr-xr-x 4 root root 4096 Mar 4 15:29 ..
drwxr-xr-x 2 root root 4096 Mar 4 15:32 hosts
-rw------- 1 root root 1680 Mar 4 15:32 rsa_key.priv
-rwxr-xr-x 1 root root 72 Mar 4 15:30 tinc-down
-rwxr-xr-x 1 root root 80 Mar 4 15:30 tinc-up
-rw-r--r-- 1 root root 218 Mar 4 15:31 tinc.conf
ls -la /etc/tinc/tincnet/hosts
drwxr-xr-x 2 root root 4096 Mar 4 15:32 .
drwxr-xr-x 3 root root 4096 Mar 4 15:32 ..
-rw-r--r-- 1 root root 484 Mar 4 15:32 OpenWRT_Public_Node
cat /etc/tinc/tincnet/tinc.conf
Name = OpenWRT_Public_Node
AddressFamily = ipv4
BindToAddress = * 11001
Interface = tinctun0
Device = /dev/net/tun
#Mode = <router|switch|hub> (router)
Mode = switch
ConnectTo = Linux_Public_Node
Cipher = aes-128-cbc
cat /etc/tinc/tincnet/tinc-up
#!/bin/sh
ip link set $INTERFACE up
ip addr add 192.168.212.6/24 dev $INTERFACE
cat /etc/tinc/tincnet/tinc-down
ip addr del 192.168.212.6/24 dev $INTERFACE
ip link set $INTERFACE down
cat /etc/tinc/tincnet/hosts/OpenWRT_Public_Node
Address = 1.1.1.1
Subnet = 192.168.212.6/32
Port = 11001
-----BEGIN RSA PUBLIC KEY-----
MIIBCgKCAQEA6Tzot1eXupi+NRCfr29iKbgiXEMW1Ol327WOrAwRtiwGgQIx8LcL
iy9m+sZEWVzlfvhMub6RVM4xlZ39ghYn2OFP4x9K4D6O/HTZHbamuLOEG5zRyVGK
EN+tTStIeEaiHad04QR+6ZFB+UO7WFcBzwVh/rysOL96KaUoU9VeYHVAIkubNsvA
aNSFbmqGYpl5FrXv+sJjMyGRXjc9Lb3q/FWmPApvo/9FTElHx0xH7wvAZnc7mTCH
DB6DN62A1McgydGpn7NLnuFFEeVQf3SI9TqvajcA3vXS8P9RWuRoF5HivZIL5Ebn
FJg0UkyJcWXHUNRczdfTACF6ha0ewk8T9QIDAQAB
-----END RSA PUBLIC KEY-----OpenWRT下需要再对/etc/config/tinc进行以下修改
cat /etc/config/tinc
config tinc-net tincnet
option enabled 1
option Name OpenWRT_Public_Node
config tinc-host OpenWRT_Public_Node
option enabled 1
option net tincnet下面要做的就是先将两个Master节点的hosts文件夹各自补充对方的节点信息,简单来说就是复制自己那份过去对面,保证两个节点的hosts文件夹都有全部节点的hosts信息
% ls -la /etc/tinc/tincnet/hosts
total 16
drwxr-xr-x 2 root root 4096 Mar 4 15:37 .
drwxr-xr-x 3 root root 4096 Mar 4 15:25 ..
-rw-r--r-- 1 root root 486 Mar 4 15:25 Linux_Public_Node
-rw-r--r-- 1 root root 485 Mar 4 15:37 OpenWRT_Public_Node
% cat Linux_Public_Node
Address = 2.2.2.2
Subnet = 192.168.212.8/32
Port = 11001
-----BEGIN RSA PUBLIC KEY-----
MIIBCgKCAQEAp7F+8s8lukRv0qaE5hzrQmuy2MPb8hlte/G0pcfnBCVjIL5foJ7P
LZQrTGTsKjRbPzJ9gfZUXiZRkaA+G6Q4DBOVEt41cTceZTgAzL3ief3H6MNXQ0xW
1Wo8kDNlg6g+QJq8iV5j7adJnEPivrDm4CWl8MRmVOckisnQbseKXeuzIYDhpZLA
nlIIGMzhk3OZoPn2xpdMbJqbR0K6SrPvYq7sT3eLn0NVUbyo9D1dmtwtOJy8wmaf
oYdwTvrMdXhNNUmemnswJt8T2j8rAerqnjqz5itN8dk9mZMTKLFZ44CNnJ8jl5pE
ma8lfUnAA/Qq7i9t74pVEvWcLg8HIry16QIDAQAB
% cat OpenWRT_Public_Node
Address = 1.1.1.1
Subnet = 192.168.212.6/32
Port = 11001
-----BEGIN RSA PUBLIC KEY-----
MIIBCgKCAQEA6Tzot1eXupi+NRCfr29iKbgiXEMW1Ol327WOrAwRtiwGgQIx8LcL
iy9m+sZEWVzlfvhMub6RVM4xlZ39ghYn2OFP4x9K4D6O/HTZHbamuLOEG5zRyVGK
EN+tTStIeEaiHad04QR+6ZFB+UO7WFcBzwVh/rysOL96KaUoU9VeYHVAIkubNsvA
aNSFbmqGYpl5FrXv+sJjMyGRXjc9Lb3q/FWmPApvo/9FTElHx0xH7wvAZnc7mTCH
DB6DN62A1McgydGpn7NLnuFFEeVQf3SI9TqvajcA3vXS8P9RWuRoF5HivZIL5Ebn
FJg0UkyJcWXHUNRczdfTACF6ha0ewk8T9QIDAQAB
-----END RSA PUBLIC KEY-----最后通过systemctl,OpenWRT通过RC启动tinc, 并互ping测试一下
#Linux_Public_Node systemctl
systemctl start tinc@tincnet
#OpenWRT_Public_Node rc
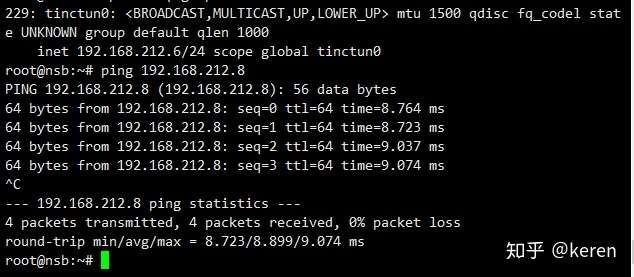
/etc/init.d/tinc startping from Linux_Public_Node(192.168.212.8) to OpenWRT_Public_Node(192.168.212.6)
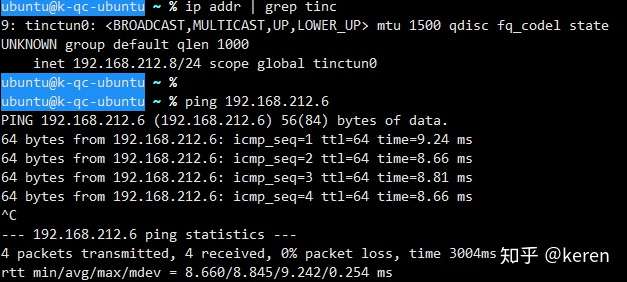
ping from OpenWRT_Public_Node(192.168.212.6) to Linux_Public_Node(192.168.212.8)
(2)其他节点的部署(Slave节点)
Linux系统以节点OpenWRT_Internal_Node(192.168.212.12)为例
同样,先按照之前的文件夹结构创建好对应目录,并复制两个Master节点hosts信息到hosts文件夹,
ls -la /etc/tinc/tincnet/
drwxr-xr-x 3 root root 0 Mar 4 16:01 .
drwxr-xr-x 4 root root 0 Mar 4 15:52 ..
drwxr-xr-x 2 root root 0 Mar 4 16:01 hosts
-rw------- 1 root root 1676 Mar 4 16:01 rsa_key.priv
-rwxr-xr-x 1 root root 74 Mar 4 15:58 tinc-down
-rwxr-xr-x 1 root root 82 Mar 4 15:58 tinc-up
-rw-r--r-- 1 root root 209 Mar 4 16:00 tinc.conf
ls -la /etc/tinc/tincnet/hosts/
drwxr-xr-x 2 root root 0 Mar 4 16:01 .
drwxr-xr-x 3 root root 0 Mar 4 16:01 ..
-rw-r--r-- 1 root root 0 Mar 4 15:58 Linux_Public_Node
-rw-r--r-- 1 root root 454 Mar 4 16:01 OpenWRT_Internal_Node
-rw-r--r-- 1 root root 0 Mar 4 15:58 OpenWRT_Public_Node
cat /etc/tinc/tincnet/
hosts/ rsa_key.priv tinc-down tinc-up tinc.conf
cat /etc/tinc/tincnet/tinc.conf
Name = OpenWRT_Internal_Node
Interface = tinctun0
Device = /dev/net/tun
#Mode = <router|switch|hub> (router)
Mode = switch
ConnectTo = Linux_Public_Node #此处需要配置链接到两个主节点
ConnectTo = OpenWRT_Public_Node #此处需要配置链接到两个主节点
Cipher = aes-128-cbc
cat /etc/tinc/tincnet/tinc-up
#!/bin/sh
ip link set $INTERFACE up
ip addr add 192.168.212.12/24 dev $INTERFACE
cat /etc/tinc/tincnet/tinc-down
ip addr del 192.168.212.12/24 dev $INTERFACE
ip link set $INTERFACE down
cat /etc/tinc/tincnet/hosts/OpenWRT_Internal_Node
Subnet = 192.168.212.21/32 #只需要配置Subnet参数
-----BEGIN RSA PUBLIC KEY-----
MIIBCgKCAQEAnU1maDEvbyC2XJLC8aiiwixR+einVu9gyJ4Pi1uhNMSJuVHB0HLQ
s16eOJvoEeJ4q6x0YLwjVJLlcLRW46wUAr1eMLjiovGKcYL8fZCg+Agms3+0y2SM
MaKi5fgBKjXLhdeBx4pvLaBlgYz4BP7pcVLgI0/NHBR6K1PClUtYDN1xCt5SOpiF
XIwyIawwIs6mxLknm7M0a68j7e3ovIsBOW7nLVL0GpLXVJBjAbs5z00uNOVaNJkz
tvttShGgaa+B6o1Xy8gLwB84wKNUXZbmkLobOK7h0qYgEmnQscR8Rhw5G9UJfU8G
8nrPdRRCZnDR5xRpuy0rRJG7gAzpEJ9kHwIDAQAB
-----END RSA PUBLIC KEY-----
#以下为OpenWRT系统需要配置
cat /etc/config/tinc
config tinc-net tincnet
option enabled 1
option Name OpenWRT_Internal_Node
config tinc-host OpenWRT_Internal_Node
option enabled 1
option net tincnet然后需要复制hosts文件夹的本节点信息host\OpenWRT_Internal_Node到Master节点的hosts文件夹中,重启tinc服务即可通,
ping 192.168.212.8
PING 192.168.212.8 (192.168.212.8): 56 data bytes
64 bytes from 192.168.212.8: seq=0 ttl=64 time=25.108 ms
64 bytes from 192.168.212.8: seq=1 ttl=64 time=8.567 ms
64 bytes from 192.168.212.8: seq=2 ttl=64 time=8.891 ms
64 bytes from 192.168.212.8: seq=3 ttl=64 time=8.745 ms
^C
--- 192.168.212.8 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 8.567/12.827/25.108 ms
ping 192.168.212.6
PING 192.168.212.6 (192.168.212.6): 56 data bytes
64 bytes from 192.168.212.6: seq=0 ttl=64 time=7.328 ms
64 bytes from 192.168.212.6: seq=1 ttl=64 time=6.871 ms
64 bytes from 192.168.212.6: seq=2 ttl=64 time=7.205 ms
64 bytes from 192.168.212.6: seq=3 ttl=64 time=7.130 ms
^C
--- 192.168.212.6 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 6.871/7.133/7.328 ms再配置一个Windows系统的,
首先需要新增一个TAP-Windows的虚拟网卡,以另外安装的新版本TAP-Windows驱动为例,管理员权限运行CMD
C:\Users\k>cd C:\Program Files\TAP-Windows\bin
C:\Program Files\TAP-Windows\bin>.\addtap.bat
C:\Program Files\TAP-Windows\bin>rem Add a new TAP virtual ethernet adapter
C:\Program Files\TAP-Windows\bin>"C:\Program Files\TAP-Windows\bin\tapinstall.exe" install "C:\Program Files\TAP-Windows\driver\OemVista.inf" tap0901
Device node created. Install is complete when drivers are installed...
Updating drivers for tap0901 from C:\Program Files\TAP-Windows\driver\OemVista.inf.
Drivers installed successfully.
C:\Program Files\TAP-Windows\bin>pause
请按任意键继续. . .
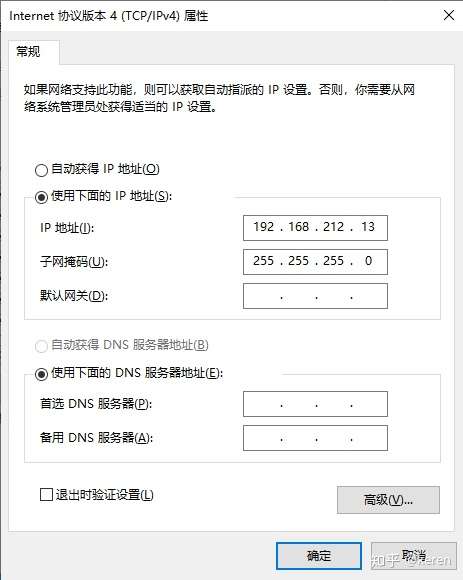
到网络连接管理中重命名网卡名称并手动配置IP地址
然后创建好文件目录
C:\Program Files\tinc\tincnet 的目录
2020/03/04 16:14 <DIR> .
2020/03/04 16:14 <DIR> ..
2020/03/04 16:16 <DIR> hosts
2020/03/04 16:17 167 tinc.conf
1 个文件 167 字节
3 个目录 144,868,106,240 可用字节
C:\Program Files\tinc\tincnet\hosts 的目录
2020/03/04 16:16 <DIR> .
2020/03/04 16:16 <DIR> ..
2020/03/04 16:16 499 Linux_Public_Node
2020/03/04 16:16 496 OpenWRT_Public_Node
2020/03/04 16:16 27 Windows_Internal_Node
3 个文件 1,022 字节
2 个目录 144,864,964,608 可用字节C:\Program Files\tinc\tincnet\tinc.conf
Name = Windows_Internal_Node
Interface = tinctun0
#Mode = <router|switch|hub> (router)
Mode = switch
ConnectTo = OpenWRT_Public_Node
ConnectTo = Linux_Public_NodeC:\Program Files\tinc\tincnet\hosts\Windows_Internal_Node
Subnet = 192.168.212.116/32生成密钥
C:\Program Files\tinc>.\tinc.exe -n tincnet
tinc.tincnet> generate-rsa-keys
Generating 2048 bits keys:
...................................................+++ p
......................+++ q
Done.
Please enter a file to save private RSA key to [C:/Program Files\tinc\tincnet\rsa_key.priv]:
Please enter a file to save public RSA key to [C:/Program Files\tinc\tincnet\hosts\Windows_Internal_Node]:
tinc.tincnet> quit
C:\Program Files\tinc>然后将带公钥信息的Windows_Internal_Node复制到两个Master节点上面重启节点
通过Windows计算机管理中的服务启动tinc
PING其他Slave节点测试
C:\Program Files\tinc>ping 192.168.212.12
正在 Ping 192.168.212.12 具有 32 字节的数据:
来自 192.168.212.12 的回复: 字节=32 时间=12ms TTL=64
来自 192.168.212.12 的回复: 字节=32 时间=11ms TTL=64
来自 192.168.212.12 的回复: 字节=32 时间=12ms TTL=64
来自 192.168.212.12 的回复: 字节=32 时间=11ms TTL=64
192.168.212.12 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 11ms,最长 = 12ms,平均 = 11ms
如果还有新增节点,那么只需在节点本地创建好配置文件以及hosts信息,然后将本节点的hosts信息复制到Master节点上面即可。
(3)节点的NAT配置
这个是补充内容,比如Slave节点OpenWRT_Internal_Node的br-lan网卡有另一网段192.168.1.0/24的地址192.168.1.1,那么如果我想在Windows_Internal_Node通过OpenWRT_Internal_Node的 tincnet地址192.168.212.12:8080直接访问OpenWRT_Internal_Node 192.168.1.0/24网段中的192.168.1.20:80,那么可以可以通过NAT直接实现。
具体iptables配置如下:
iptables -A input_rule -i tinctun+ -j ACCEPT
iptables -A forwarding_rule -i tinctun+ -j ACCEPT
iptables -A forwarding_rule -o tinctun+ -j ACCEPT
iptables -A output_rule -o tinctun+ -j ACCEPT
iptables -t nat -A PREROUTING -i tinctun0 -p tcp -d 192.168.212.12 --dport 8080 -j DNAT --to-destination 192.168.1.20:80
iptables -t nat -A POSTROUTING -s 192.168.212.0/24 -o br-lan -j SNAT --to 192.168.1.1refer: https://vnf.cc/2020/03/openwrt-tinc/
Docker OpenWrt Builder
Docker OpenWrt Builder
Build OpenWrt images in a Docker container. This is sometimes necessary when building OpenWrt on the host system fails, e.g. when some dependency is too new. The docker image is based on Debian 10 (Buster).
Build tested:
- OpenWrt-21.02.2
- OpenWrt-19.07.8
- OpenWrt-18.06.9
A smaller container based on Alpine Linux is available in the alpine branch. But it does not build the old LEDE images.
Prerequisites
- Docker installed
- running Docker daemon
- build Docker image:
git clone https://github.com/strongkill/docker-openwrt-builder.git
cd docker-openwrt-builder
docker build -t openwrt_builder .
Now the docker image is available. These steps only need to be done once.
Usage GNU/Linux
Create a build folder and link it into a new docker container:
mkdir ~/mybuild
docker run -v ~/mybuild:/home/user -it openwrt_builder /bin/bash
In the container console, enter:
git clone https://git.openwrt.org/openwrt/openwrt.git
cd openwrt
./scripts/feeds update -a
./scripts/feeds install -a
make menuconfig
make -j4
After the build, the images will be inside ~/mybuild/openwrt/bin/target/.
Usage MacOSX
OpenWrt requires a case-sensitive filesystem while MacOSX uses a case-insensitive filesystem by default.
Create a disk image:
hdiutil create -size 20g -fs "Case-sensitive HFS+" -volname OpenWrt OpenWrt.dmg
hdiutil attach OpenWrt.dmg
Then run:
docker run -v /volumes/openwrt:/home/user -it openwrt_builder /bin/bash
(Source)
Usage Windows
TODO
Other Projects
Other, but very similar projects:
ANKEE 1.1.9 for Android
The description of ANKEE App
Control your ANKEE smart home device
ANKEE App 1.1.9 Update
2019-07-13
display brightness value in light control page
IAR for STM8的簡介、下載、安裝及註冊教程
一、簡介
1.關於IAR for STM8
IAR for STM8 是一個嵌入式工作平台,主要應用於STM8 系列芯片的開發,現在(2018年3.10版本)能夠支持市面上所有的STM8芯片。
個人認為,IAR for STM8和Keil差別並不是很大,只要熟悉Keil的使用,那上手IAR for STM8並不是什麼難事,網絡上也有許多相關資料可以查詢。
2.關於該篇博客
這一篇博客主要來講解一下IAR的下載、安裝、註冊的步驟,
雖然說的是IAR for STM8的教程,
但其實ARM跟其他的下載、安裝步驟類似的。

大家可以從我的百度雲下載IAR for STM8(3.10版本)和註冊機!!!
鏈接:https://pan.baidu.com/s/16UHwCZkgONEeLwiwBawAhg
提取碼:gvj9
二、下載IAR for STM8軟件(以下兩種下載方法均可)
1.從官網下載
網址:https://www.iar.com/iar-embedded-workbench/#!?architecture=STM8
2.百度雲下載
鏈接:https://pan.baidu.com/s/1KU6QKuLZXysiwo9J_b0fPQ
提取碼:3nf0
三、安裝IAR for STM8軟件
軟件安裝就比較簡單了,這裡就沒什麼難的地方~
只要從一開始的這個界面,一直點“next”、“yes”、“是”……就能順利安裝完成~
安裝完成後進入軟件界面,如下:

四、軟件註冊
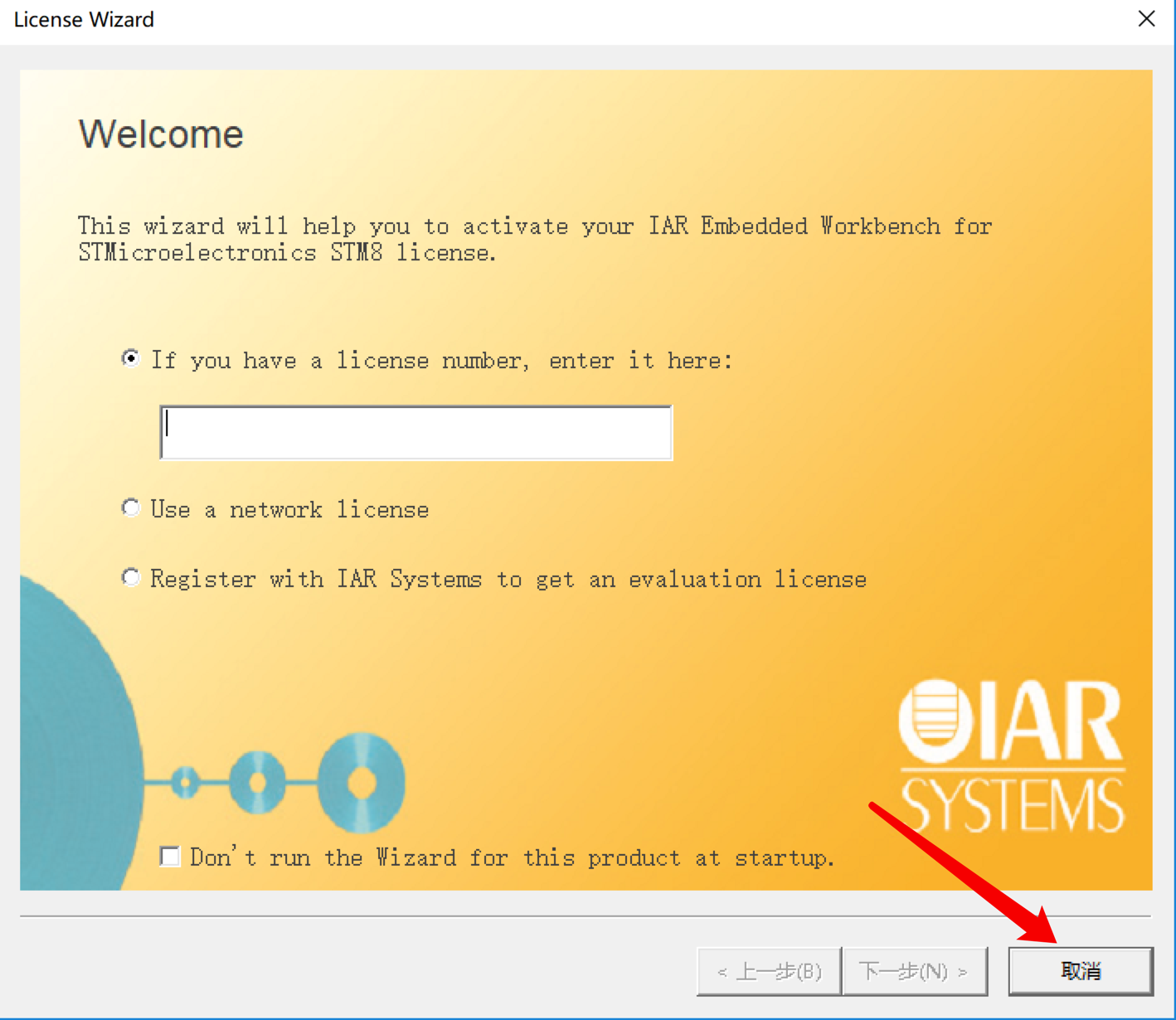
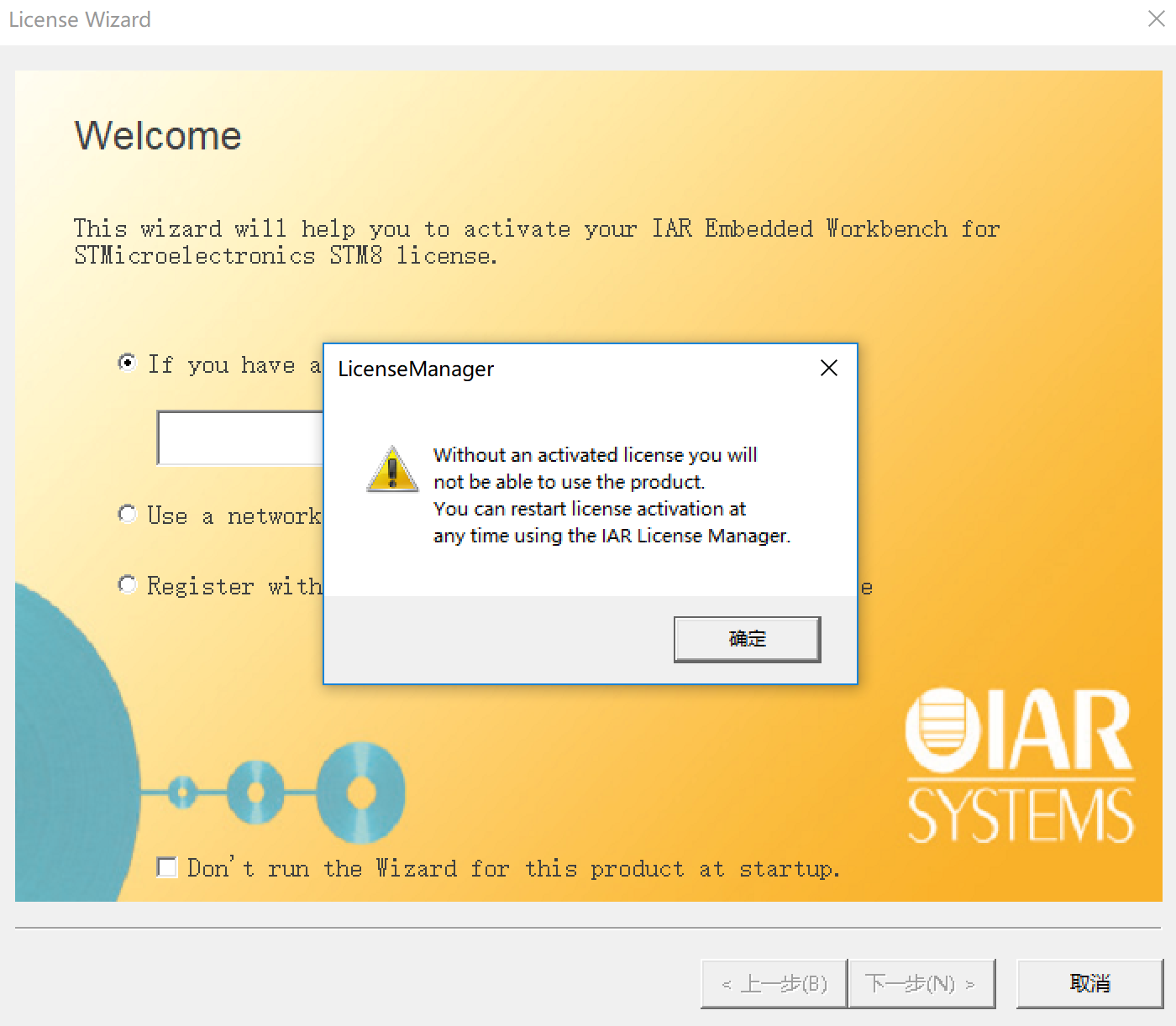
1.打開軟件IAR Embedded Workbench IDE:License Manager ->“取消”->“確定”
License Manager:
“取消”:
“確定”:
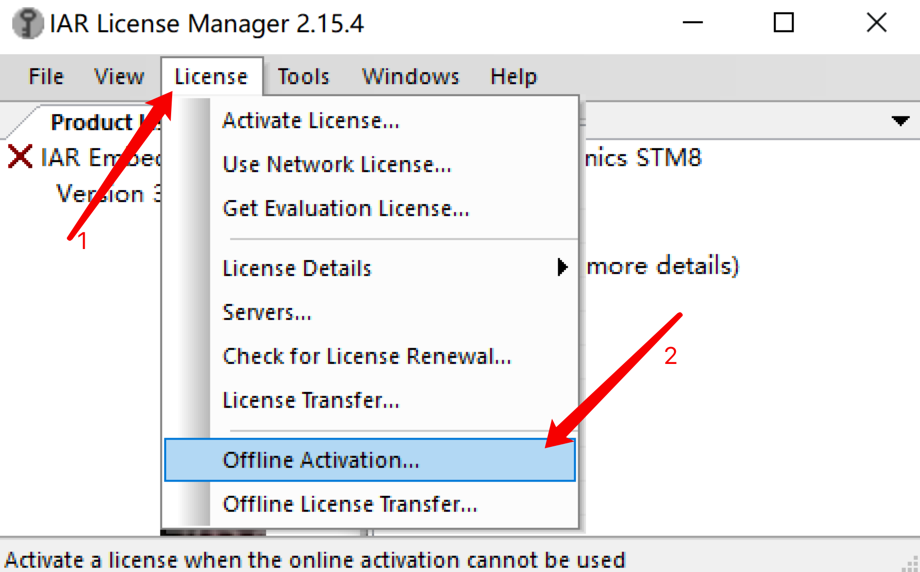
2.許可管理License Manager:“License”->“Offline Activation”(離線激活) ->“License Wizard”
License Manager:
點擊“License”->“Offline Activation” :
License Wizard:
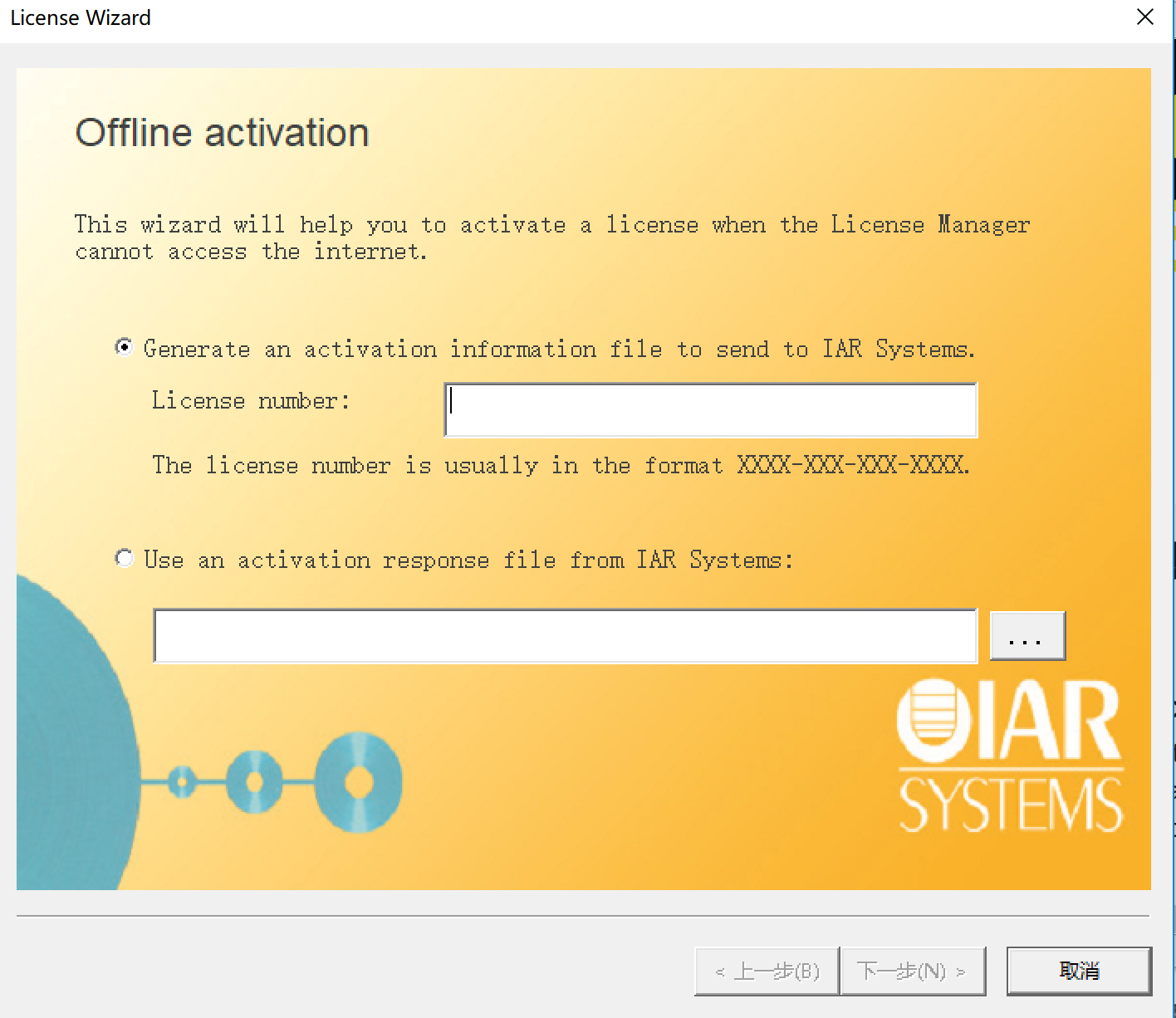
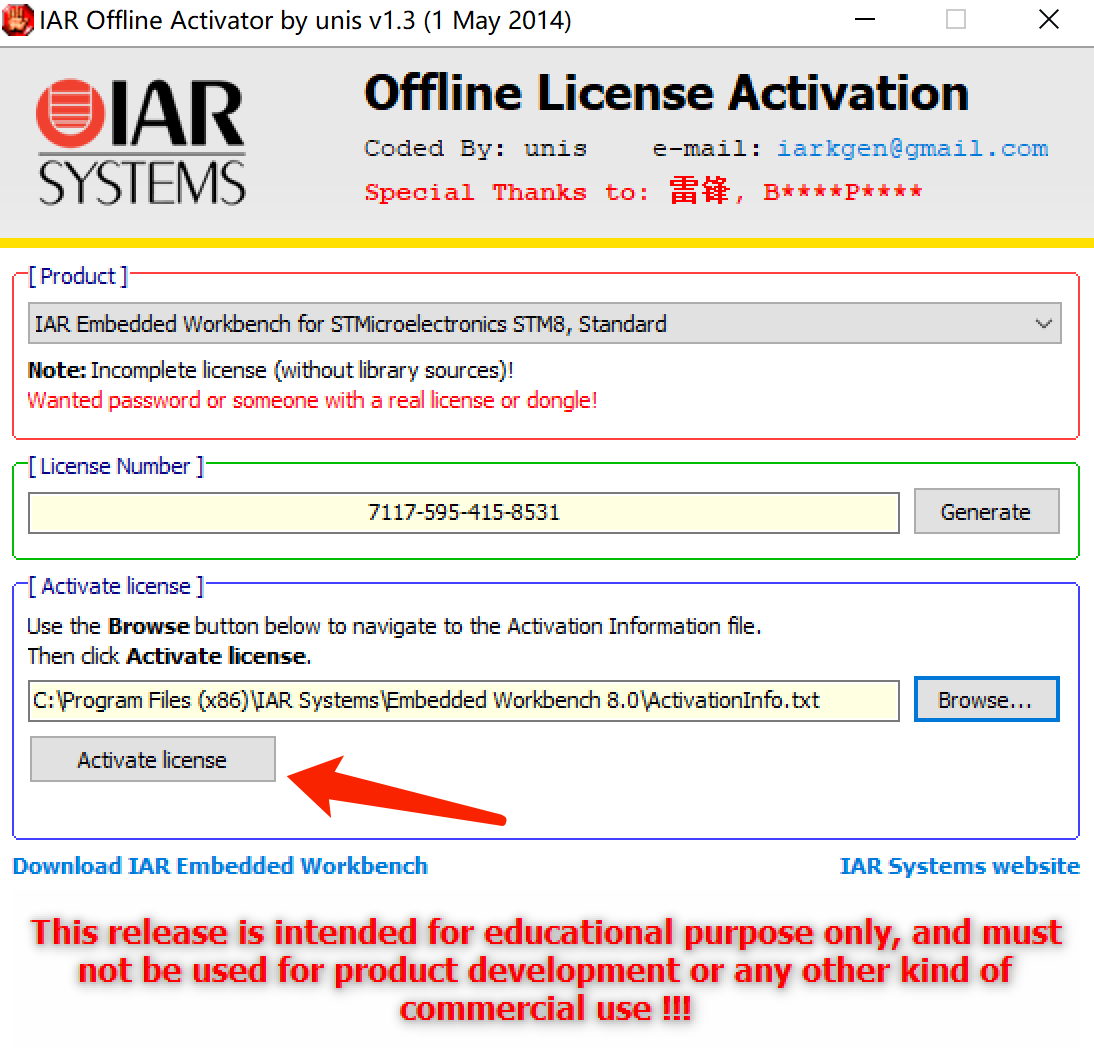
3.打開註冊機: 選STM8->生成許可碼->複製
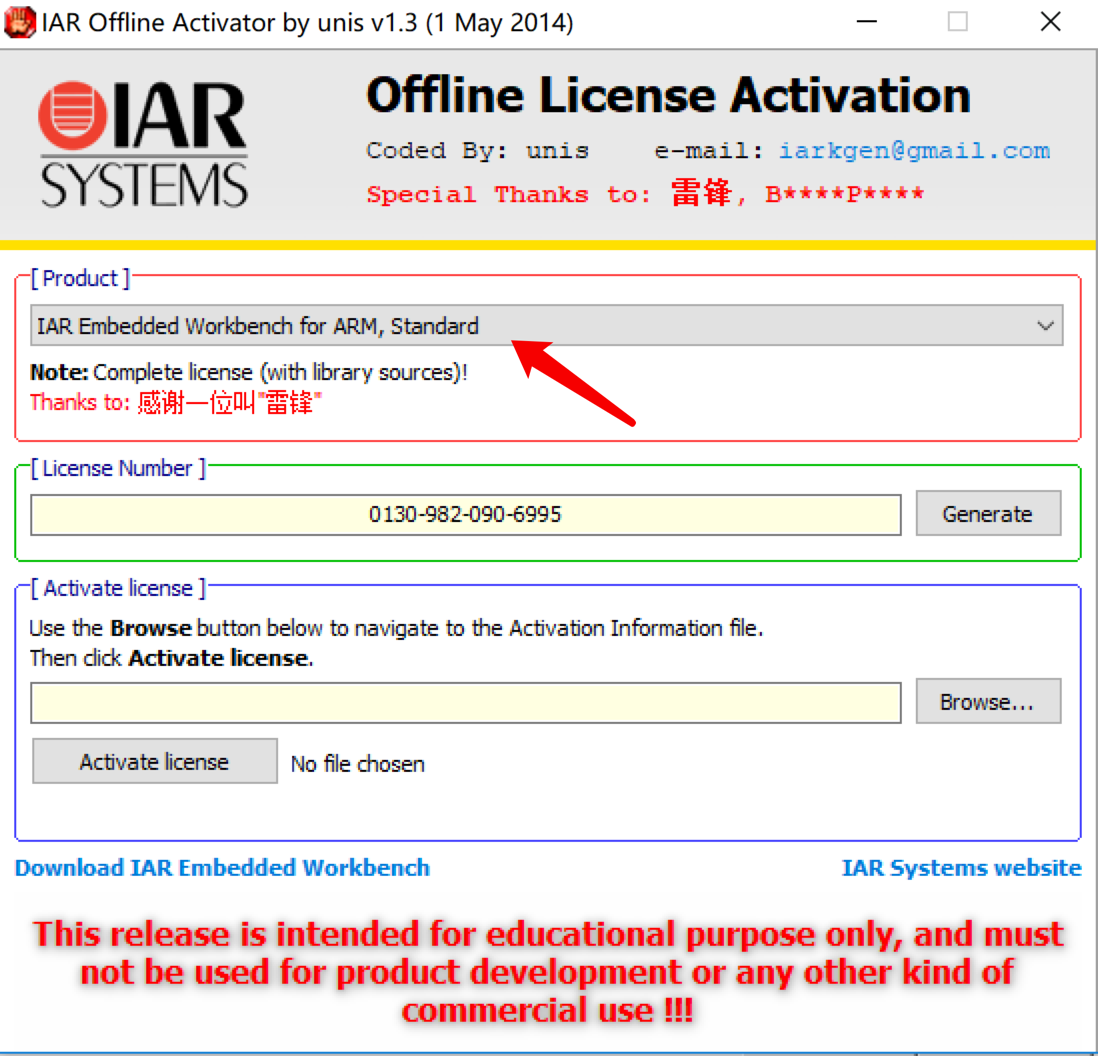
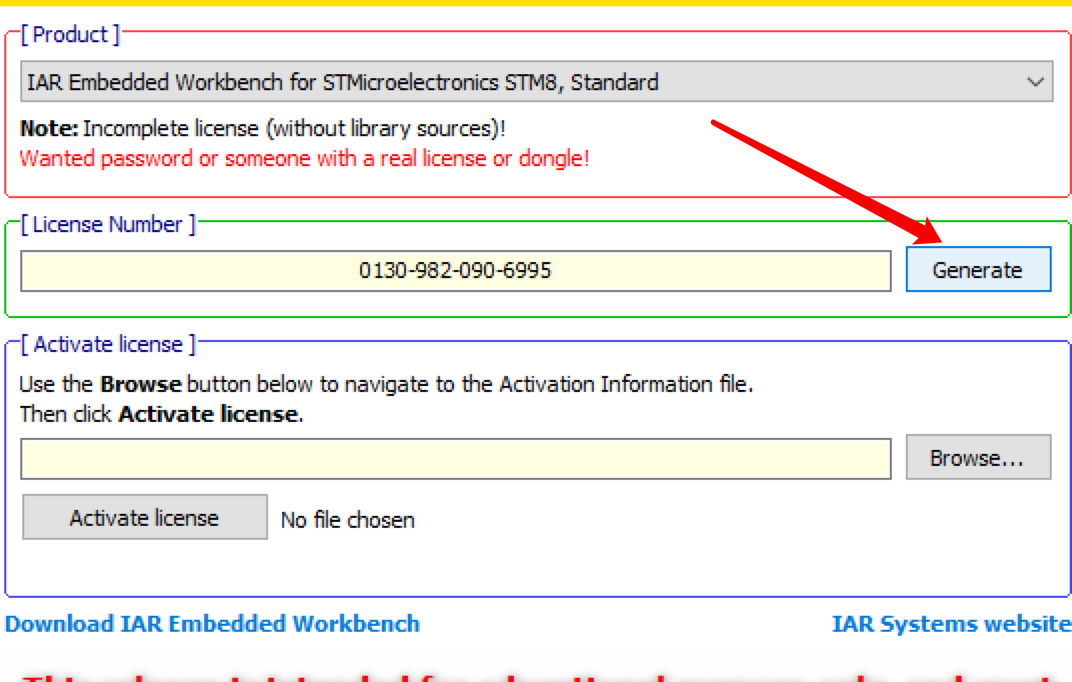
選擇STM8:

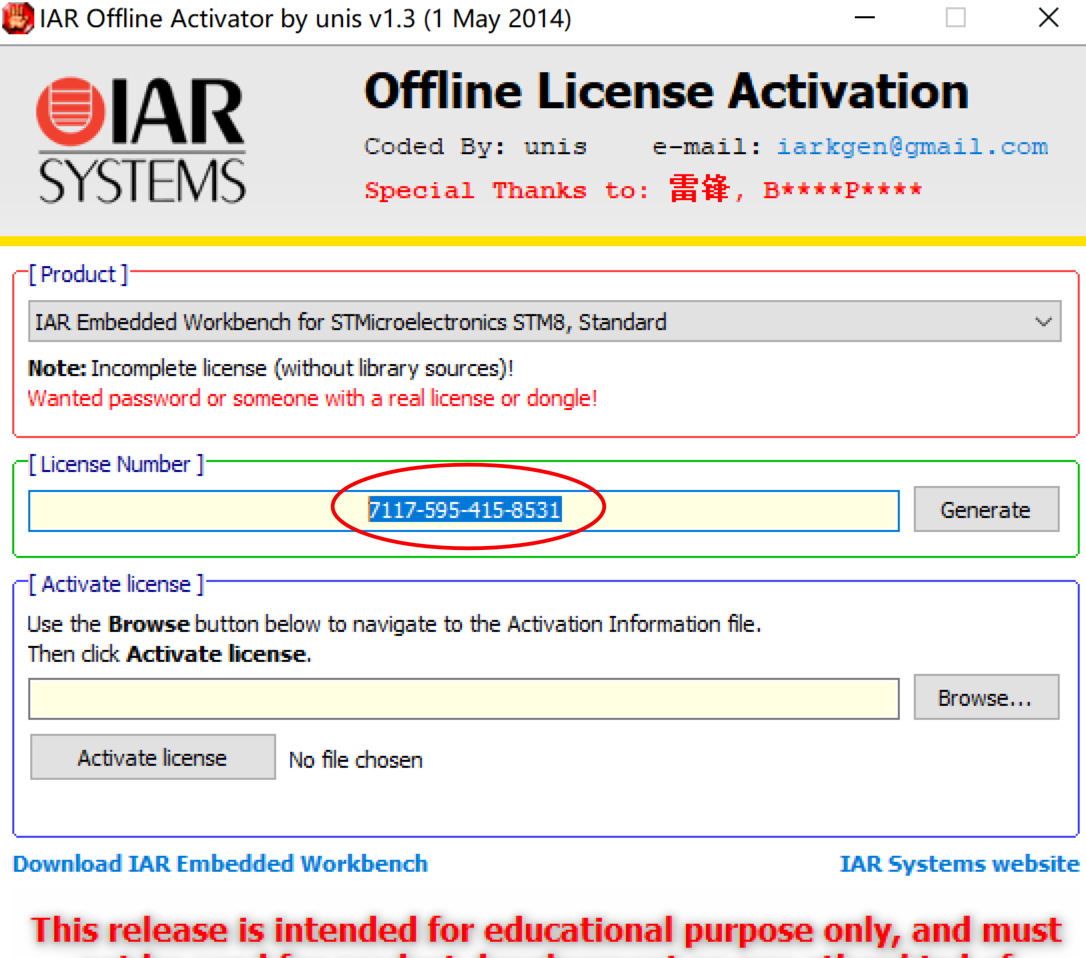
生成(Generate):
複製:
4.激活界面:黏貼->下一步->……

選擇“No” :

選擇存儲路徑:
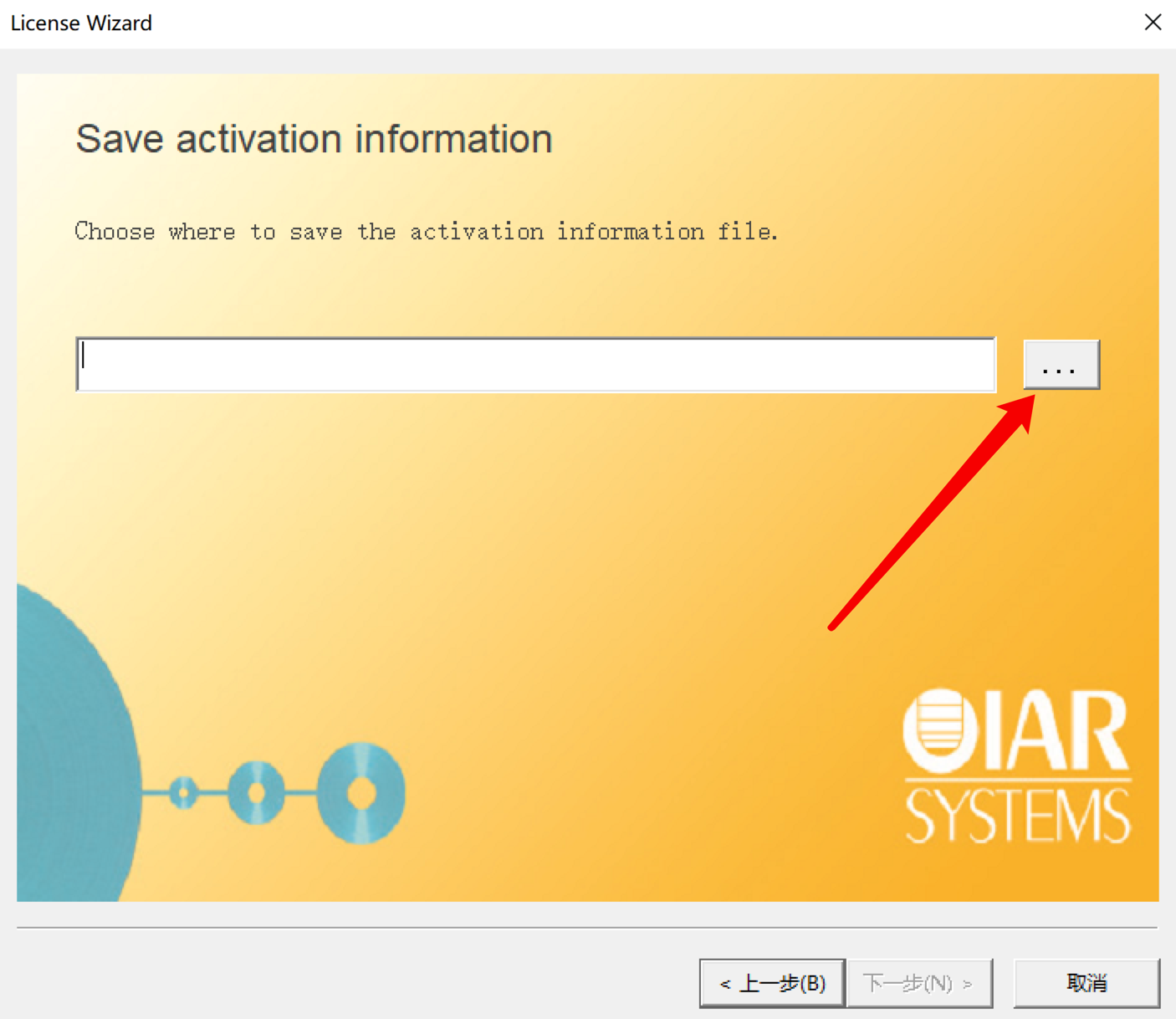
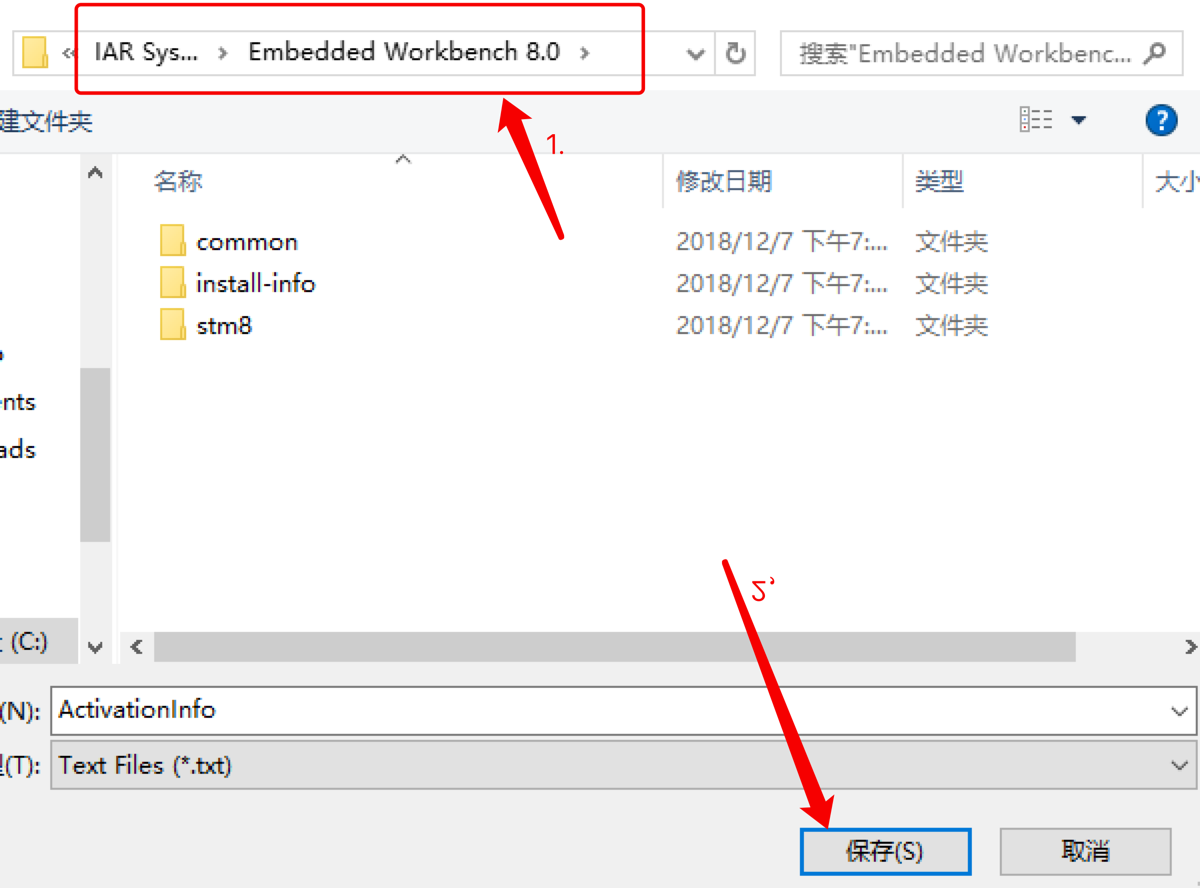
放在此路徑下:

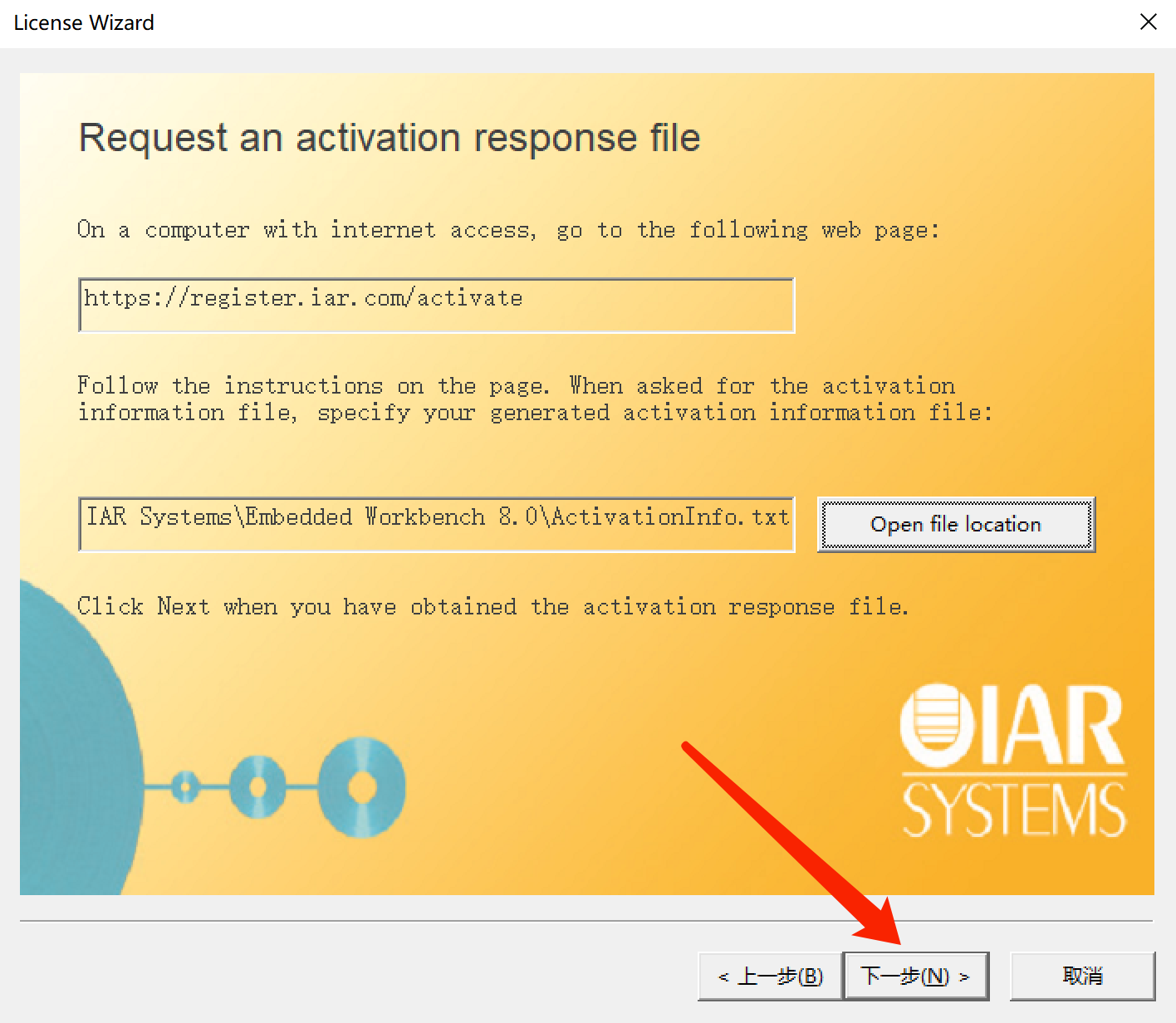
請求激活信息界面:
5.註冊機:選擇剛才存儲的文件->
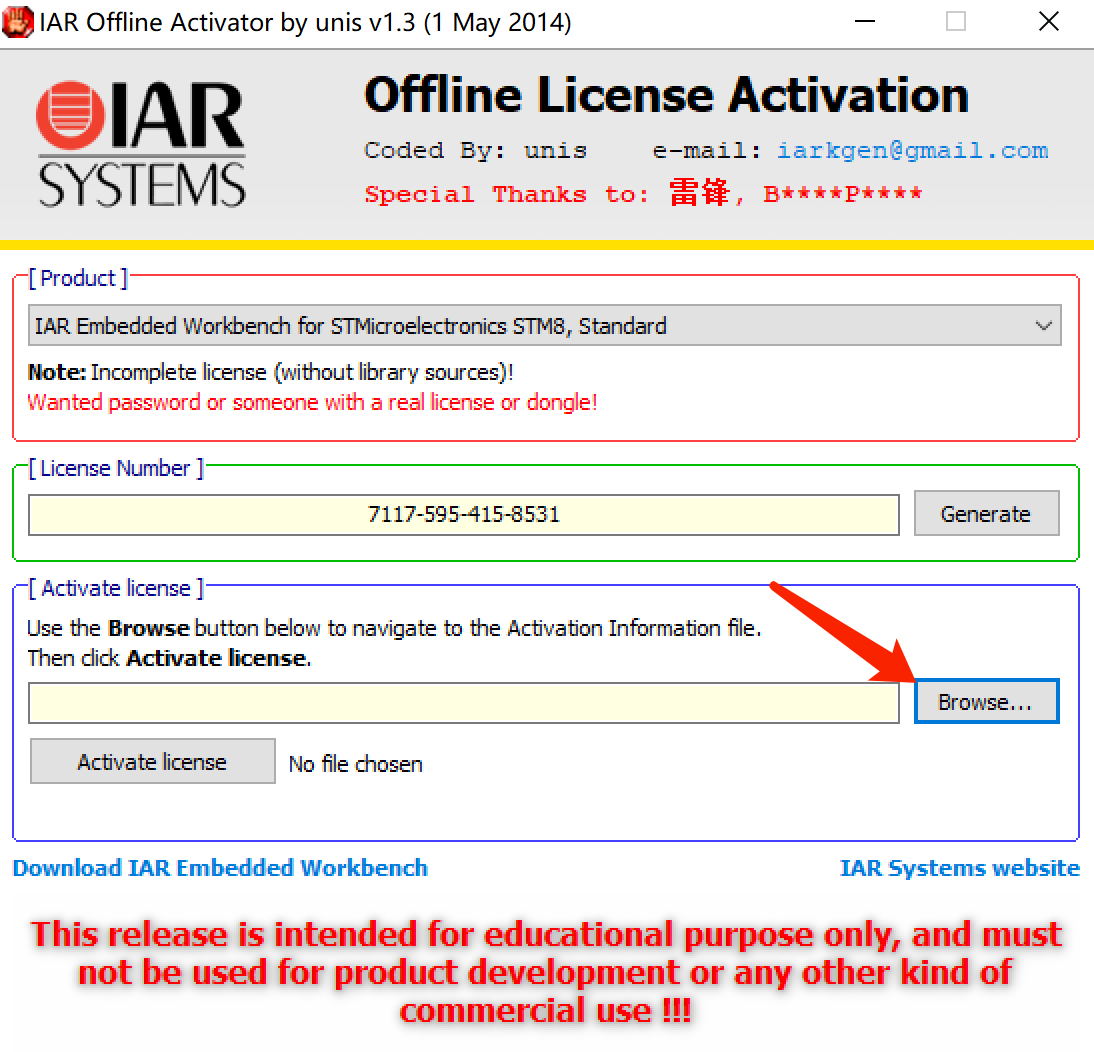
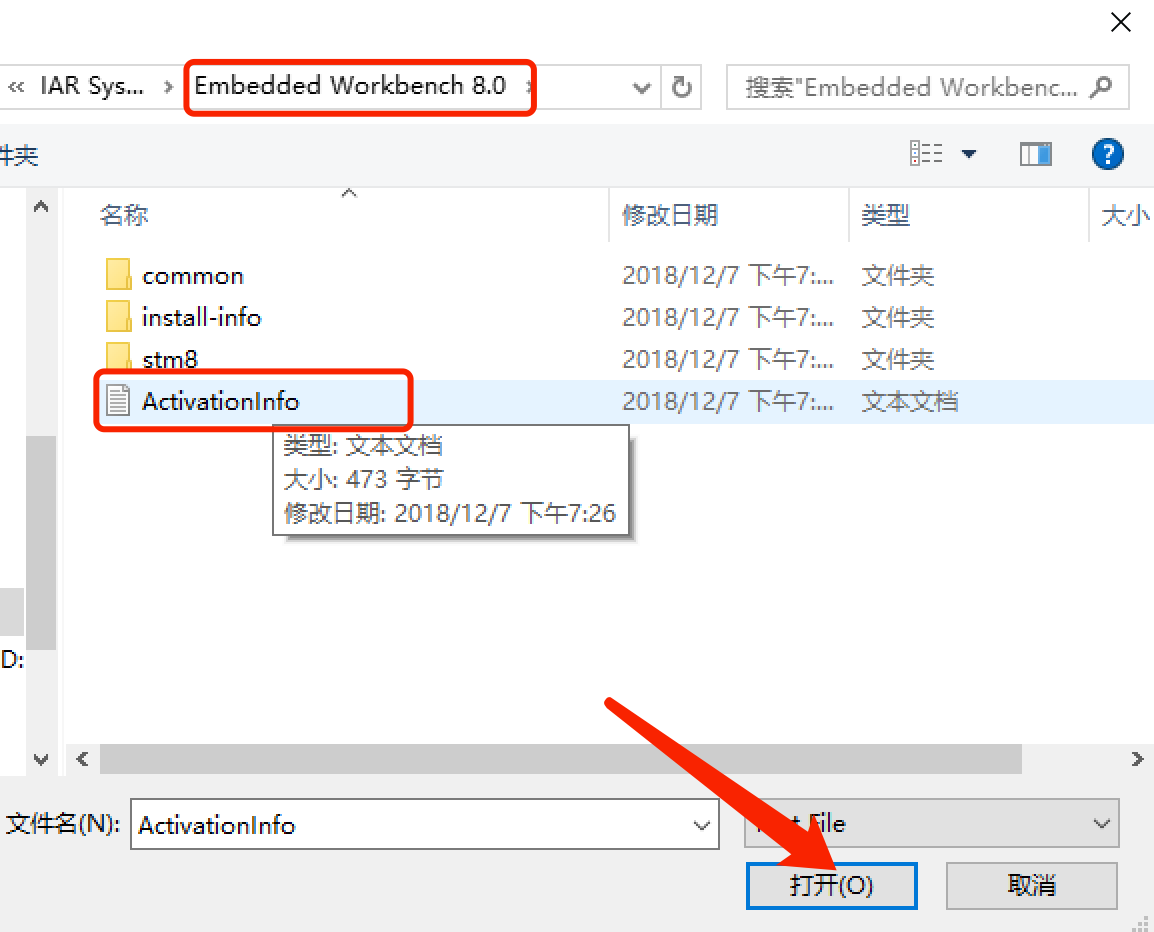
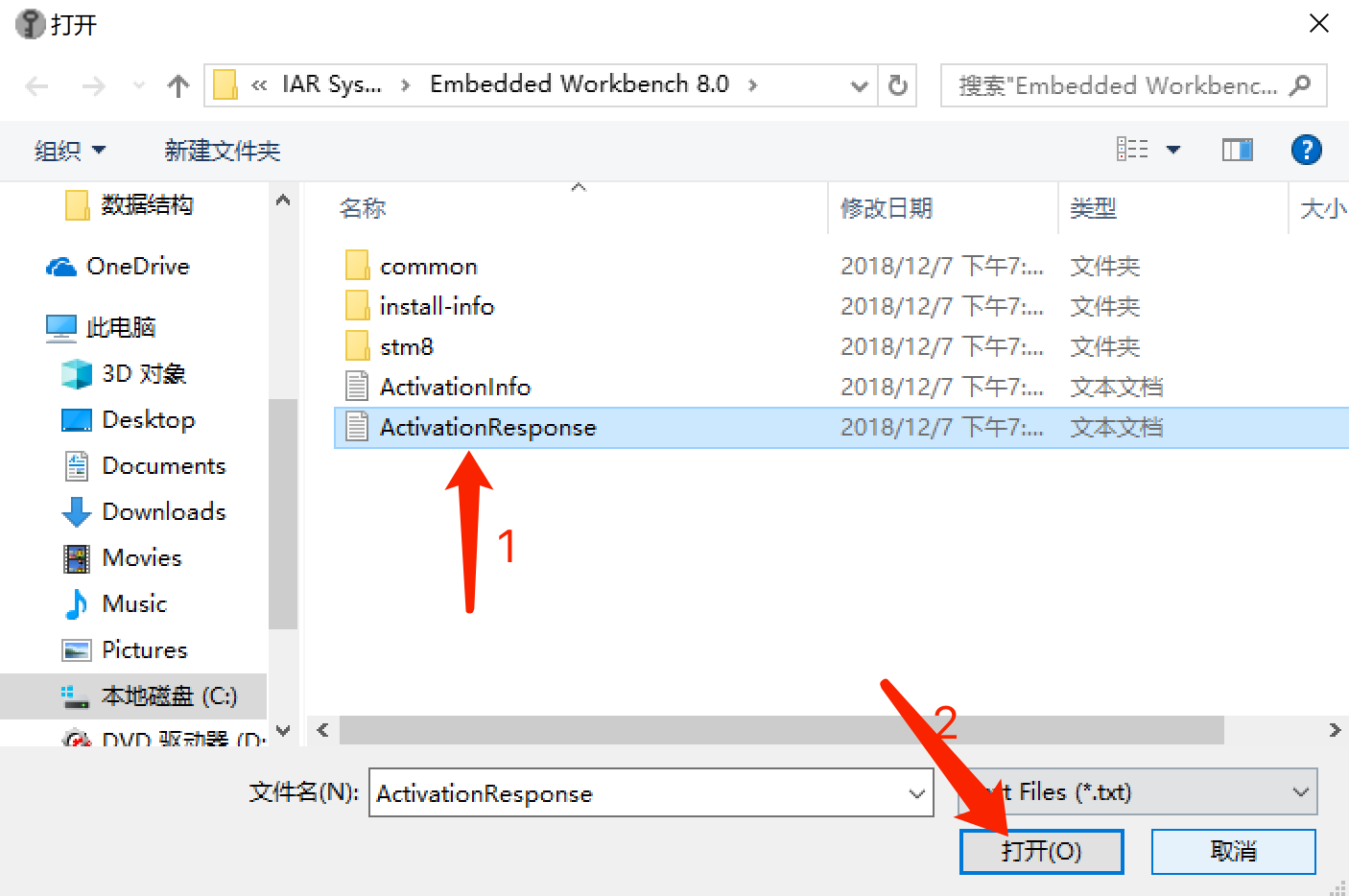
點擊後生成新的文件:
再選取新生成的文件:
點擊下一步:

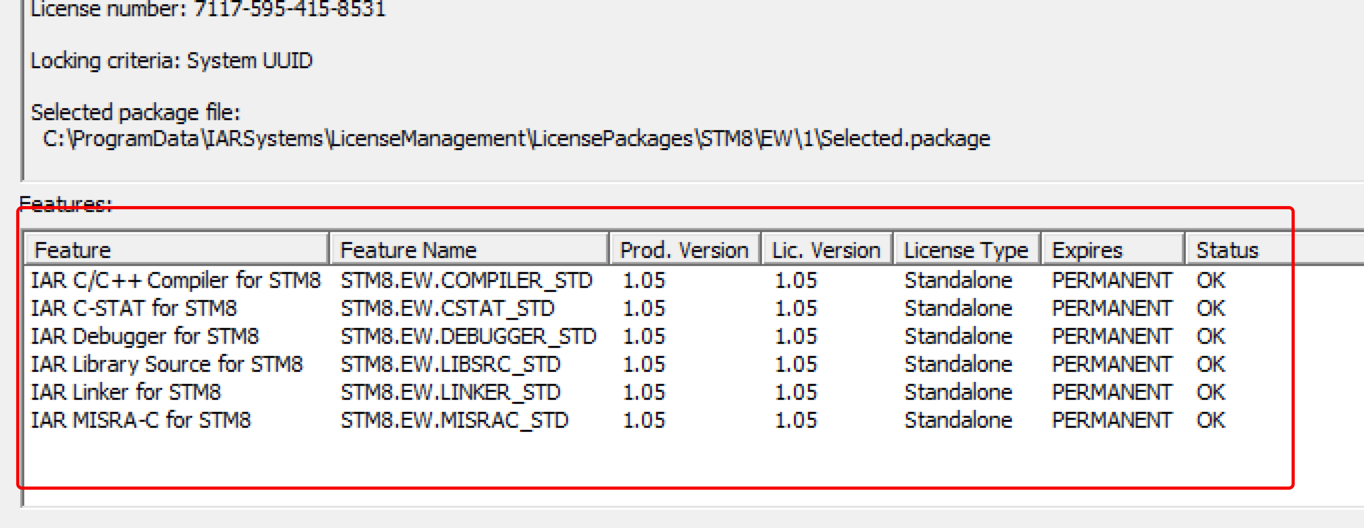
6.檢查註冊狀況:
雙擊:
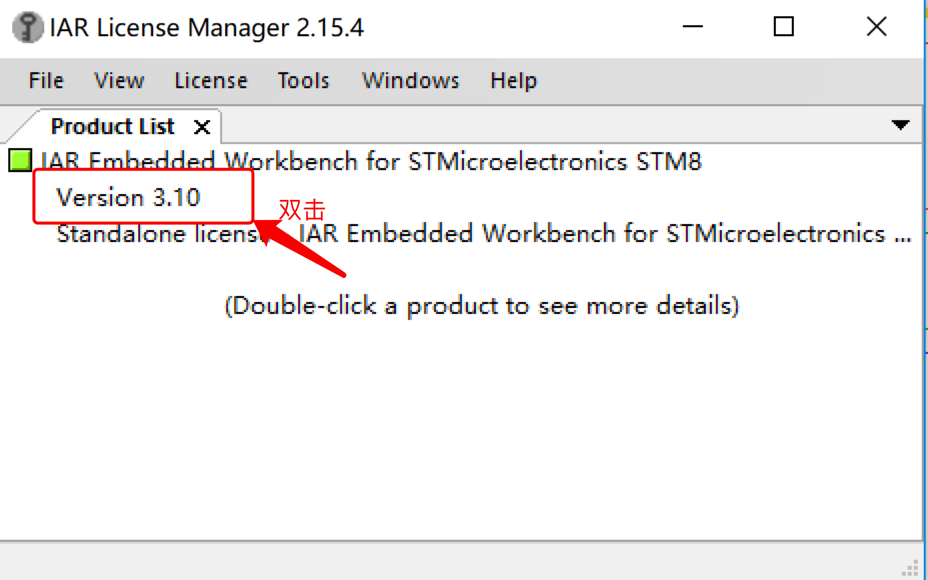
顯示狀態都是“ok”,那就恭喜註冊成功!!!
事到如今,IAR for STM8 已經完全可以使用了。
希望能幫助到有需要的朋友~
移動端H5真機調試方案
今年入職了一家做直播的公司,主要是負責APP中內嵌webview頁面的開發,之前移動端兼容經驗比較少,對於我來說最大的困擾就是網頁兼容性問題。
在Chrome瀏覽器的模擬器進行開發調試已經完美完成了需求之後,一到驗收或者上線,就出現各種兼容引起的bug,要解決還特別曲折,不僅要探索Android和iOS手機的不同調試方式,還要支持在不同瀏覽器或者APP上調試,極大的影響了開發的效率。
雖然我們也可以通過模擬器進行開發調試,但模擬終究是模擬,在某些場景下真機還是不可或缺,尤其是特定機型版本的問題。
一般情況下,真機Web調試要怎麼做呢?
一、vConsole
npm地址: github.com/Tencent/vCo…
介紹: vConsole插件是一個移動端輕量可擴展的工具,其功能和電腦端的控制台基本一致,能運行JS代碼、查看cookie、抓包等
使用: 在head中添加如下代碼即可
<script src="https://cdn.bootcss.com/vConsole/3.3.4/vconsole.min.js"></script>
<script>
// 初始化
var vConsole = new VConsole();
console.log("hello vconsole");
</script>
复制代码如果是想通過npm安裝或者對於TypeScript的使用方式請去倉庫查看!
調試:
面板:
其實和console控制台一樣,打開一個頁面的時候,下方會出現一個綠色的“vConsole”按鈕,點擊按鈕即可打開控制台,在“log”頁面中輸入JS代碼,即可執行腳本,“Network”頁面為分析網絡會話列表,“System”頁面顯示協議頭User-Agent、系統信息網絡狀態等信息,“Storage”頁面為cookie信息等
二、Eruda
npm地址: github.com/liriliri/er…
介紹: Eruda 是一個專為前端移動端、移動端設計的調試面板,類似Chrome DevTools 的迷你版(沒有chrome強大這個是可以肯定的),其主要功能包括:捕獲console 日誌、檢查元素狀態、顯示性能指標、捕獲XHR請求、顯示本地存儲和Cookie信息、瀏覽器特性檢測等等。
使用: 在head中添加如下代碼即可
<script src="//cdn.jsdelivr.net/npm/eruda"></script>
<script>eruda.init();</script>
复制代码Eruda 的使用方法和麵板跟vConsole差不多,更詳細的使用方法可去官方倉庫查看!
三、Fildder
下載地址: www.telerik.com/fiddler
介紹: Fiddler是最強大最好用的Web調試工具之一,它能記錄所有客戶端和服務器的http和https請求,允許你監視,設置斷點,甚至修改輸入輸出數據,Fiddler無論對開發人員或者測試人員來說,都是非常有用的工具
使用: 1、下載安裝並配置好fillder工具
2、手機和fildder鏈接同一個網絡,然後手機開啟手動代理並安裝證書
a.配置手動代理
b.下載證書手機瀏覽器地址輸入代理的主機名和端口(10.0,5.155::8888)
c.安裝證書
上面步驟完成後然後打開H5頁面,如果能在fildder抓到頁面資源表示抓包成功
3、然後線上或則測試環境有問題的相關文件或者頁面代理到本地調試
AutoResponder不僅可以代理文件,還能代理接口返回等,代理成功後就可以在本地文件中debugger斷點一步步調試,找出線上真機出現的問題
四、調試本地Vue項目步驟
1、手机和fildder软件同一个网络
2、手机网络设置手动代理,ip为电脑网络的ipv4地址,端口为fiddler设置的端口默认8080
3、手机浏览器输入代理的地址+端口,安装证书
4、本地项目跑起来,如果是域名访问的,则需要配置hosts
5、手机打开访问的地址就可以debugger调试了
复制代码
作者:Liben
链接:https://juejin.cn/post/6907546374422659079
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。